22 June 2021
Technical SEO Checklist for PHP applications


There are many ways to improve the visibility of your web application in Google search results. You can create great content or take advantage of a variety of SEO techniques. But you will not only achieve your full SEO potential unless your app is SEO-ready from a technical point of view. Here is an up-to-date technical SEO checklist for PHP apps and more.
Search Engine Optimization is a process aimed at improving visibility in the search engine result pages (SERPs). SEO focuses on increasing organic traffic and consists of three main pillars:
- technical optimization,
- content,
- backlinks.
As a developer, am I able to make my web application perform better in SERP or at least help it become more cooperative with the efforts of SEO specialists?
In this article, I‘m going to prove that I can. In the process, I’m going to share with you a technical SEO checklist that I’m using in my own projects.
Let’s get right to it!
1. Application Performance
Google now makes it clear that speed and overall performance of your app are a factor that matters in Google Search. Let’s break it down.
Core Web Vitals and WTH does it mean?
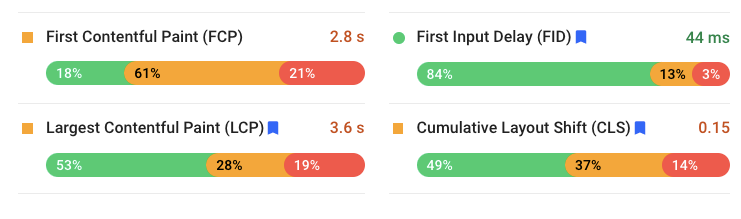
The concept of Core Web Vitals is designed by Google to evaluate the user experience on a website. The metrics have been divided into LCP, FID and CLS. Apparently, the indicator should indicate at least 75%.
LCP, which is the Largest Contentful Paint, is the time it takes for the website to load the largest content element in the viewport. This metric should be smaller than 2.5 seconds to provide a good user experience.
Which elements are connected with the LCP?
- <img> tag,
- <image> tag set in <svg>,
- <video> tag,
- an element that uses url() function in its CSS,
- block-level text elements such as <p> <div> <table> .
FID, or the First Input Delay, is the time it takes to start interacting with the website. For example, it is the time between the start of loading and the moment the browser is able to respond to an interaction. This metric should be smaller than 100ms for best results.
What is connected with the FID?
- Every event that can freeze the browser such as network requests for JS and CSS files.
- Parsing and executing a large JS file loaded by your application.
CLS, or the Cumulative Layout Shift, is an indicator that measures any unexpected content shifts that occur while your site is loading. It’s annoying when you are reading an article and the content is being pushed by an ad. The unexpected movement of page content has to do with an asynchronous script that can add some DOM elements.
Before I start improving the performance of the web app, I need to create a performance report.
It is going to provide plenty of useful metrics such as those described above and many more. It gives me a point of reference for future improvements.
Whenever I have to check those metrics, I use Google’s PageSpeed Insights, but there are more tools that can help you inspect the website’s performance and Core Web Vitals.
Optimizing the app’s performance
My goal is to verify and improve the LCP and FID and the website’s speed as much as I can. But how do I do it?
- CDN Caching stores files in the data centers, where they can be rapidly accessed. It moves your website content to powerful proxy servers optimized for fast distribution. This type of website caching is offered by the largest players on the market such as AWS, Google Cloud Platform or Cloud Flare.
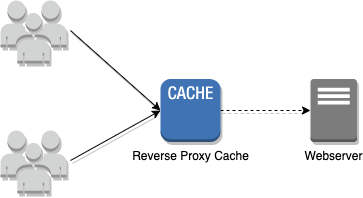
- A cache is a very important part of our infrastructure. On the one hand, the cache allows me to save server resources and on the other hand, it accelerates rendering. But what and where can I cache? I recommend Redis. Redis is an open-source in-memory database. If the application uses the Doctrine ORM, it is possible to configure a second-level cache using a Redis driver. It allows Doctrine to store results from the database in your Redis.
- Command and Query Responsibility Segregation pattern allows me to manage the returned content better. I create read models which are designed specifically for the content. This solution limits the number of queries to the database and allows me to serve readable format data for the frontend. Additionally, it improves order in the code because, of course, nobody likes mess in the code. Am I right?
Learn more about the CQRS patterns from this 4-part series from my colleague Michał Żądło:
- Limit the number of requests on first site loading. Check how many resources a browser has to download, e.g. in CSS. How can I do this? One way is to implement a webpack in the project and serve a single CSS file for the frontend.
What type of plugins do I use?
- Minification of CSS and JavaScript files and HTML code – for smaller files.
- Image compression – sometimes I don’t need high-quality graphics in the template. Plugins like these allow me to compress images automatically:
- Gzip/Brotli/Deflate – for file compression.
- Defer loading non-critical JS/CSS – if you have JavaScript, which is not necessary for loading the app and also to render, defer it. It will no longer block the process of rendering.
Onto the next one!
2. Server-Side Rendering (SSR) or Client Side Rendering (CSR)?
Between these two options, SSR is much better for SEO.
Why? Because full JavaScript websites built on libraries like React or Angular might appear nearly totally blank for crawlers. Of course, modern crawlers such as Googlebot can read JS-rich sites but it takes more time. Besides, rendering tasks might take much more time on a client-side, which affects website loading time. Be safe and choose SSR.
Learn more about Server Side Rendering with Next.js.
3. Canonical Tag
If you have the same content available on several URLs, the Google crawler will recognize them as duplicated content. Very often this problem occurs in the case of pages that accept parameters in the address.
How to deal with this situation? The canonical link comes to help. You have to add a canonical link to the original URL – let’s check some examples below:
Let’s say we have a blog post:
https://tsh.io/blog/message-broker/
Which is going to be also available with query strings:
https://tsh.io/blog/message-broker/?some=query
https://tsh.io/blog/message-broker/?sort=date
https://tsh.io/blog/message-broker/?order=asc
For Google, those URLs are unique and in case of query string there are endless combinations of URLs, which might be very dangerous and have a negative impact on the website’s ranking (just imagine thousands of URLs with the same content indexed in Google). Cleaning up a mess like this can take a while.
It’s a good practice to always implement canonical tag in the <head> section – just remember about few rules:
- Canonical links must have an absolute URL address.
- It means you have to provide protocol, host and path. Skip the query string and other bits (#).
- The canonical link will always point to itself and in case of URLs with query strings, it’s going to always point to the URL ending at the path (of course, I assume your app is using friendly URLs. I mean, come on, it’s 2021 already):
https://tsh.io/blog/message-broker/
<link rel=”canonical” href=”https://tsh.io/blog/message-broker/” />
https://tsh.io/blog/message-broker/?some=query
<link rel=”canonical” href=”https://tsh.io/blog/message-broker/” />
https://tsh.io/blog/message-broker/?sort=date
<link rel=”canonical” href=”https://tsh.io/blog/message-broker/” />
https://tsh.io/blog/message-broker/?order=asc
<link rel=”canonical” href=”https://tsh.io/blog/message-broker/” />
This implementation prevents the app from indexing the duplicate content. Of course, there are more complex situations like “similar” content and so on, but it’s not clearly backend-related stuff, so leave it for SEO experts.
4. Robots.txt
The robots.txt file tells the search crawlers which pages and files on your site can be crawled. It’s mainly used to keep your site from getting overloaded with requests.
Robots.txt file might be tricky in terms of SEO, but from your perspective just make sure to always follow one general rule – do not block CSS and JS files! Otherwise, Googlebot won’t be able to fully render the website.
In the majority of the cases below, the robots.txt file rules are good enough. Treat them as a starter point and extend if needed.
Oh, and don’t forget to always place the robots.txt file in the public root directory! It needs to be available at the https://example.com/robots.txt address.
If you would like to block your site for Google, don’t block it in the robots.txt file, but add this tag between your <head> tag:
If Googlebot finds that tag the next time, it will deindex the page that contains this tag from Google search results.
5. Schema.org – what is structured data and how to manage it?
Schema.org aims to standardize the interpretation of web content by search engines. Thanks to structured data, Googlebot better understands what is on the website. But is Schema.org really necessary? No.
However, the situation when the bot interprets the content well is better for the website. An additional argument may be extended information in the form of Rich Snippet – for example, star-rating, price or availability info directly in Google SERP. They allow our website to be distinguished in the search engine results.
Libraries for PHP are available to assist with creating schema.org. One of them is spatie/schema-org, which generates the JSON-LD script recommended by Google.
In the next snippet, I’m going to show you how to use this library.
The result of this snippet will be the tag <script type=”application/ld+json”></script> , which should be in the website’s head section.
How to check if our JSON-LD is correct? I use this simple testing tool.
6. Friendly URLs
Friendly URLs are a very important part of SEO. This seemingly simple thing has some pitfalls.
- Links should be short and human-readable too. Each address should indicate clearly the content which we will get by clicking on the address.
- Links should contain only lowercase letters and “-” as space replacement. When the application allows us to create these two URLs below for the same content, the Googlebot will recognize them as two unique pages with duplicate content:
- Links should not have parameters in the address. Why? Because it can cause duplicate content for Googlebot. If you must have parameters, just use the canonical meta tag.
- https://tsh.io/blog/message-broker/?sort=asc it will be a new duplicated content,
- https://tsh.io/blog/message-broker.
7. Response codes traps
Page status codes during certain events are a big problem in the SEO world. Here is a list of some traps that are worth attention:
Soft 404s
The problem occurs when a resource is not found, but the webserver returns code 200 instead of 404.
Using redirection with 302 code
302 is a temporary redirect, so Google can still keep the old resource in the index (even if the user is redirected). There’s almost no situation where you’ll need 302, so bear in mind to always use 301 (permanent) redirection.
Redirect chains
Pay attention to whether the website has redirect chains such as A -> B -> C -> D. The redirect from content A should indicate directly to content D.
Site maintenance with 200 code
Do you have maintenance mode on your site? Make sure the HTTP server returns the 503 code there. You really don’t want to re-index the whole website with your maintenance screen,
Domains redirections
The website should be available only from one address otherwise Google will recognize every domain as duplicated content. The site can be invoked with those options:
- http://www.domain,
- http://domain,
- https://www.domain,
- https://domain.
I recommend choosing only one option (preferably with SSL) and configuring the web server well.
Internal links
Make sure your app always serves internal links with proper URLs. Avoid:
- internal links pointing to 404,
- internal links pointing to redirect chains.
8. XML Sitemap file
Simply, this is a file that contains a list of all your website’s page URLs. It helps Googlebot discover your website during the crawling process. There’s no rocket science involved here. This simple file or files might boost the entire crawling and indexing process.
Don’t forget to let Googlebot know where your XML sitemap is (via the robots.txt file).
Pro-tip! The XML sitemap file doesn’t have to be stored at the same domain where your website is (but usually is). This is why you need to point the full address (absolute – protocol, host, path) where the sitemap is.
9. Mixed content
If your website is secured with the HTTPS protocol (it should), then make sure you don’t download any external or internal resources (such as CSS, JS, images, fonts and so on) via the unsecured HTTP protocol.
Technical SEO Checklist – summary
As you can see, the SEO world is quite complex and dynamic. Developers can make life easier for your SEO team by following some simple rules. By adapting a website to the Google search engine, we can improve many aspects beyond PHP.
Of course, some practices need to be implemented at the design level, but remember, that there is always a way to SEO-improve your project that is available to you as a developer.
Did you know that according to “KPI Report 2020”, SEO is responsible for 43% of web traffic?
You can learn this and much more from out State of Frontend 2020 report, which highlights the importance of SEO in modern web development among many other factors!

