28 January 2022
CQRS and Event Sourcing implementation in PHP

Command Query Responsibility Segregation (CQRS) with Domain Driven Design is more and more popular recently. Its implementation in PHP, which will be the topic of the article, generates some new possibilities, making a process more efficient. For example, it gives you the opportunity to restore the whole system easily. Also, it enables asymmetric scalability, guarantees no data loss and many more. In this article, I’m going to talk about CQRS and Event Sourcing implementation in PHP extensively.
Before I step to the CQRS and Event Sourcing implementation in PHP – I’ll try to briefly explain what is the general concept behind CQRS. In 1986, Bertrand Meyer came up with an idea of Command Query Separation (CQS). According to the concept – each method in the object in its current state must belong to only one category out of the following two:
- command – a method which changes an object’s state,
- query – a method which returns the data.
It means that all the queries like these should return the same result as long as you didn’t change the object’s state with a command.
See also: 4Developers 2018: The road to true knowledge
As you can see below, in the first example – the rule is broken by the method increase() which shouldn’t return the value. In the second one, there is a presentation of proper implementation.
I’m mentioning that because using CQRS pattern is derived directly from the same concept. However, it’s not related to the object/component but rather to the whole system or bounded context, which is logically separated part of such a system, responsible for a realisation of certain tasks. Let’s take an example of a simple webstore. We can separate the following contexts: a purchase, a delivery or a complaint.
Using Command Query Responsibility Segregation (CQRS pattern)
You can ask – how to use CQRS pattern?
CQRS is a style of application’s architecture which separates the “read” operations and the “write” operations on the bounded context level. It means that you create 2 data models – one for writing and the other for reading. It’s presented on the scheme below.
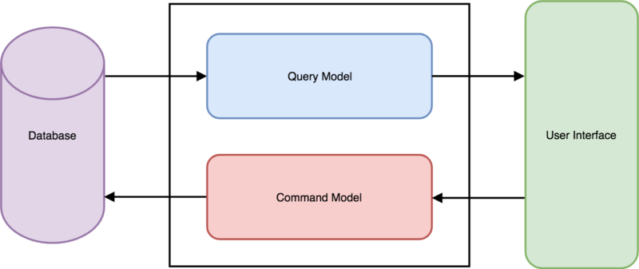
As you can see, implementation of a logic responsible for writing is independent of an implementation of a logic responsible for reading. In practice, it enables a better fit of the Read/Write models to the requirements. A read side may be flattened and may serve aggregated data. At the same time – it doesn’t have to calculate these in real-time. In the case of a common model of read/write, this kind of data is redundant and it only introduces unnecessary “chaos”, complicating a writing model in current state.
What is Event Sourcing and Event Store?
Let’s imagine a basic example of making an order in a webstore with digital cameras.
- You add a camera to the cart.
- You add a memory card.
- You increase the number of memory cards up to 2.
- You make an order based on the cart content, choose the delivery and payment methods.
- You make a payment.
The whole process is a series of subsequent events. In a traditional approach, you apply the changes (which come from the above events) to the cart’s objects and then to the order’s objects. Next, you write its state in the database.
What if you write subsequent events as they happen instead of writing the final effect? In this case, reconstitution of the objects will be about creating an empty object and applying these events. This object should have exactly the same state as the one written in a database in a traditional approach.
The described method is Event Sourcing. The events connected to the object are the source of the data – not its final state.
See also: Symfony vs Zend Framework – PHP Framework comparison Part I: Documentation
Event Bus is an important element in communication between Write and Read models. Event Bus is a mechanism which enables communication between different components, which not necessarily know about each other. One of the elements is publishing events (so-called publisher) and it doesn’t know what components (known as subscribers) are using it and how many components like this are there. On the other side – the components don’t know what is publishing the events.
When using Command Query Responsibility Segregation (CQRS), all the changes are done on a write side. It generates the events which inform about the changes. The events are published through Event Bus, then these are consumed by a Read Model. Thanks to that, a Read Model is informed about all the changes and can react. In other words – it can change the status of served objects.
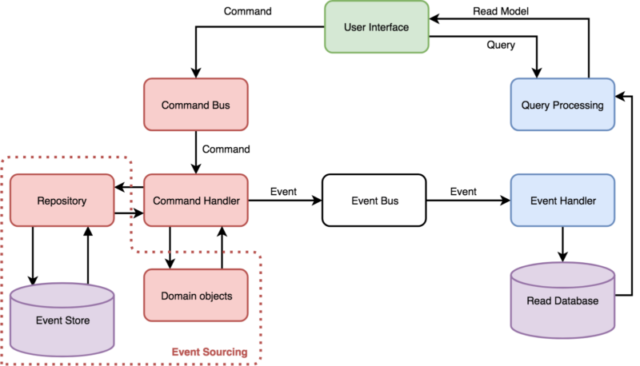
Event Store is a database optimized for events recording. In the Event Store, you can only write the events and the data connected to them. Domain objects are not written in the database, they only exist in a memory and are reproduced on the basis of events which happened.
Below, there’s an example of an event object which informs about a user creation.
As you can see, the object contains only primitive types. It’s done on purpose. Thanks to that, you can easily serialize objects to write them in the database and to store them in the message queueing systems. There, they can wait to be processed.
Need top-notch PHP developers?
Do you need help with implementing Event Sourcing and CQRS or other modern PHP solutions? At The Software House, we have a team of very talented PHP developers who will gladly help you.
Pros and cons of Event Sourcing
The Event Sourcing pattern, like any other approach, has its pros and cons.
Pros of Event Sourcing:
no event data loss; everything that happened since the system has been created with its business logic is written in Event Store,
asymmetric scalability; you can scale a part responsible for reading independently of the one dedicated for writing;
you can restore the whole system, basing on the events,
you have access to the whole history of the changes in the domain objects (natural audit),
you can divide the work in the team in a better way; writing model is normally way more complex and it requires better knowledge.
On the other hand, Event Sourcing has some cons:
- eventual consistency; not all the changes are available immediately, sometimes you need to wait for the events processing,
- the existence of two models (read/write),
- the higher complexity of the app,
- little support from frameworks/libraries.
Let’s now get to very important piece of software for Event Sourcing – the Broadway library.
What is Broadway and what components it gives us?
There are 2 libraries which give full support for using CQRS/Event Sourcing in PHP: Broadway and Prooph. Taking into consideration the fact that some components developed by Prooph will soon be cancelled (you can read more about it here) – there will be Broadway only.
But what is Broadway?
The authors come up with the below definition on the project’s official website:
Broadway is a project providing infrastructure and testing helpers for creating CQRS and event-sourced applications.
As you can see, Broadway is the library which provides the infrastructure. It enables the creation of the PHP application which is based on using Event Sourcing and using CQRS. In practice, it means that we get full support for this architecture. Broadway provides the following components:
- Auditing – logging all the commands,
- CommandHandling – support for the Command Bus,
- Domain – support for domain objects; it includes the abstraction for aggregate roots and domain message/events,
- EventDispatcher – component Event Dispatcher,
- EventHandling – event’s support,
- EventSourcing – support for event-sourced aggregate roots, event source repository implementation,
- EventStore (Doctrine DBAL, MongoDB) – support for databases for writing events,
- Processor – it supports the application’s processing,
- ReadModel (Elasticsearch, MongoDB) – support for Read Model with the database(Elasticsearch or MongoDB),
- Repository – abstraction of the storage of aggregates,
- sensitive data handling – it helps handling the events which include sensitive data (and it doesn’t save it in Event Store),
- Serializer – it supports serialization and deserialization of the data.
Let’s now talk about the implementation of the Write Model with Broadway library.
Write Model implementation

Domain
Let’s imagine that you need to implement a module to handle users in an application. They need to be able to log in and browse through the list of all the registered users.
According to the idea presented earlier, you divide the app into two parts. The first part will be responsible for saving and managing the users, the other will be delivering a simple list, which includes some basic data and enabling logging in.
Step-by-step implementation of the Write Model
So, your task is to implement a functionality which allows adding users to the repository. Let’s check what we need:
- CreateUserCommand – a command to add a user,
- CreateUserHandler – a handler to process a command,
- UserWasCreatedEvent – an event which confirms a user creation,
- UserAggregateRoot – a user domain object,
- UserRepository – a repository to save an object.
CreateUserCommand
The command is a class containing only the fields which are necessary to create a user. You can compare it to a traditional request you submit in the office. This kind of request needs to be filled and passed to be processed.
CreateUserHandler
The handler is responsible for processing a request (CreateUserCommand). It’s a place where you can find the logic responsible for user creation.

Handler code looks like this:
Please note that the class inherits from SimpleCommandHandler provided by Broadway. Thanks to that, you don’t have to call it – Broadway will do it for you. The only thing you have to do is to provide a proper method name (format: ‘handle’ + command name).
See also: Separating business logic in PHP
To create a user object, you need to use the factory method. It’ll create a domain object basing on the provided parameters. Of course, you save only a hash for the password, so the password needs to be encoded before passing through. The encoder is injected as a dependency to the handler. The last thing you have to do is to save a user using a repository which also has been injected as a dependency.
UserWasCreatedEvent
An event code looks like the one on an example below.
The object above informs you that the user has been created. It also contains its details. Here, you have another Broadway requirement – implementation of serialization/deserialization of an event. You have to do it on your own. The rest (save/read of the Event Store event) is done by Broadway.
User Aggregate Root
Aggregate Root objects have to extend a class EventSourcedAggregateRoot.Thanks to that you get the possibility to apply events and to reconstitute objects from database.
Moreover, these objects have to meet a few additional requirements. First of all – you have to make sure that your object has its identifier. That’s why you have to implement getAggregateRootId() method.
Another requirement is to implement methods which are applying the proper event. Again, you have to provide a proper method name (format: ‘handle’ + event name).

See also: Switching framework and database tools in PHP
Please note that in a constructor, you can’t set any properties. You have to create a proper event, then it’ll be processed through the method applyUserWasCreatedEvent(). This solution enables applying the events to the object whilst recreating it from the Event Store. In the listing below, I purposely skipped accessors for private properties because I didn’t want to complicate the presented code. But obviously, they are needed in the final solution.
UserRepository
To fetch and save the data in the Event Store, you have to create a proper repository (EventSourcingRepository) which you can use in your class.
EventSourcingRepository requires you to provide a few arguments:
- Event Store object,
- Event Bus object,
- a name of the class which will be operated (in the presented case it’s User),
- a class of the object factory; I chose NamedConstructorAggregateFactory, which means the use of User class factory method instantiateForReconstitution(); then all the events will be applied,
- eventStreamDecorators – an array of decorators which allow modifying events before saving them in the Event Store. You can add the metadata this way.
Additionally, I’ve created two methods to fetch the objects from the repository and save them in the same place.
It’s presented on the listing below.
This is how I’ve implemented the Write Model. Thanks to the use of Broadway, you don’t have to think about propagating the events. They will be put on Event Bus any time when a new event is saved by the repository. There they can be read by the read part of the app and used for the Read Model updates.
Let’s go to the implementation of the Read Model!
Read Model implementation
Before I’ll step further and focus on the implementation of the Read Model, I think it’s good to revise the requirements I set previously. “All the users need to be able to log in and browse through the list of all the registered users”. It’s worth specifying that a name, a surname and a username should be displayed on the list of the users.
In accordance with these requirements, you should prepare two models of the user. The first will be created for the authentication purposes – for a person trying to sign in to the system. The second model will be created to display the user on the list.
In the “classical” approach, most probably you would decide to use the same class for both cases. However, thanks to CQRS, it’s possible to split these two functions into two separate classes. It helps to customise them and to make sure they will only include the elements which are necessary to realise their tasks. Consequently, you have to implement two classes:
- SecurityUser – for the authentication purposes,
- User – for the users’ list display purposes.
Let’s start with checking how these models look like. Then, you can focus on how to create them.
See also: Getting started with the Process Manager
SecurityUser
Let’s assume that the app is based on Symfony. That’s why it’s necessary to implement its interface ‘Symfony\Component\Security\Core\User\UserInterface’ to use it during the authentication.
Besides the Symfony requirements, it’s necessary to implement a serialization interface which is required by Broadway. Thanks to that, Broadway will take care of writing and reading from a database.
As per the interface requirements, you’ll need:
- user name,
- encrypted password,
- user roles.
Consequently, SecurityUser class will look like the one on the example below.
User
You probably noticed on the listing, that the class has only a minimal data set. This data is necessary to display the list and to meet the requirements of the interface SerializableReadModel from Broadway library. You can skip the data like password or roles at this point. It’s because you don’t need it to display the list. Also, thanks to that, you minimise the risk of any sensitive data leaks.
Project
There are two user classes, which are independent and are used in different contexts. Now, you need to create these objects. In the Write Model, you create UserWasCreatedEvent which is propagated through EventBus. Read Model can read and handle these events.
A projector is a listener, it’s looking for the events issued by Event Bus. So, what are the requirements which need to be met by a projector? Name of a method which handles an event must have a special construction: “apply” + a name of an event class. In analysed case, it’s applyUserWasCreatedEvent. Also, a method needs to take a certain event as one and only parameter.
In this method, we create objects SecurityUser and User, based on the passed event and then, you write them through dedicated repositories. To simplify the example, we create both events in the same projector. It’s also possible to implement two separate projectors for each model. To write objects, you use two dedicated repositories. Let’s take a look at how to create them.
UserRepository
A repository can be created in a relatively easy way, using a factory provided by Broadway. You need to name a repository and set what kind of objects it has to handle. Also, you need to decide where you want to store the data. Broadway provides a solution for Elasticsearch and MongoDB. An example of a repository code can look like the one below.
Of course, you can also use your own implementation if the Broadway support is not enough for you or you want to use a different database.
A controller which handles users’ list display
The data about a newly created user is added to the repository. Now, you can use it. As you remember – one of the presumptions was to display the users’ list. The app is based on Symfony, that’s why you need to create a controller class. It will be responsible for handling this kind of requests. Now you need to inject the relevant repository and then, get the users from out there. Next step is to pass it through to the view. In the example below, it’s HTML, rendered from the Twig template.
Use of SecurityUser objects
The second requirement was the users’ authentication. You need to create UserProvider class which implements Symfony\Component\Security\Core\User\UserProviderInterface.
In this example, you need to inject the relevant repository which provides access to the SecurityUser objects. Also, you need to implement the methods which are required by the interface.
The implementation can look like the one on the example below.
After indicating this class as a provider in security.yaml file, you can fully enjoy having independent models and you can appreciate the other advantages of CQRS.
Write Model and Read Model – final thoughts
So, your models are independent and can be stored in different databases. In the presented scenario, any changes in display won’t affect security. If you want to add any new data to be displayed on the users’ list, you can do it without touching the part of the code which is responsible for authentication. It reduces the possibility of mistake which could weaken the security or disable signing in.
Another advantage is that your models can be tailored exactly to your needs. If you have a few users’ lists, with different range of the display fields and different range of filters, you can use separate models to all the lists. Of course, you should stay reasonable and remember not to create too many classes, because it would mean way more code to maintain. Everything should be matched to the project’s requirements.
You probably noticed that thanks to the Broadway library, you don’t have to write too much code when implementing the Read Model. You also have two different methods of storing this data (ElasticSearch and MongoDB). Thanks to that, you can easily add new models and views and the small amount of code helps with its maintenance.
That’s all about the implementation of the Read Model.
Let’s now talk about the most common issues connected to CQRS and Event Sourcing in PHP. I’ll also present some ideas on how to deal with them.
The change in requirements
The first issue you may face is the change in business requirements. It can trigger some changes in aggregate. The change may be as tiny as adding or replacing a new field in an object. Let’s assume, that you need to add to the users list the information about the time a user is a member of the group. To do this, you need information about the date of their registration. To adjust the application to the new requirements, there are some changes which need to be executed:
- adding a field with a registration date to aggregate,
- changing an event UserWasCreatedEvent the way it contains additional information about the creation date,
- changing an event handler in aggregate and in a projector.
Now you will face another problem. It’s because you already have some events registered in the Event Store. Unfortunately, these events miss the information about registration date and you need it. Let’s think about what you can do to fix it.
Adding a new event
You can create a new event UserWasCreatedVersion2Event and you can handle both in aggregate. However, it will make you have 2 similar events in aggregate which means more code to maintain. You also have to change the handler of the event UserWasCreatedEvent to make it handle an additional field. How to do it? Well, the easiest way is to set a default value, because there was no such field before.
Advantages:
- events remain unchanged,
- it doesn’t affect an efficiency,
- the complexity of the process doesn’t change.
Disadvantages:
- it’s necessary to maintain more code in aggregates and projectors,
- it’s obligatory to refactor the handler of a previous version of an event if the changes in the object require that,
- debugging is more difficult because of a lot of events of the same type.
Rewriting existing events in the Event Store
It’s a pretty controversial solution, as the complete history of aggregate is stored in the Event Store and it’s widely known that you can’t change the history. That’s why you shouldn’t modify the events in the Event Store.
Advantages:
- you always have only one version of a certain event,
- it doesn’t affect an application’s efficiency,
- you get rid of unused code.
Disadvantages:
- you change the history of events,
- you lose the real history of changes irrevocably; you can’t treat the Event Store as an audit log,
- you can make a mistake whilst rewriting events and it may cause some unpredictable results in the future,
- you have to rebuild all the Snapshots.
Upcasting
Upcasting is nothing but upgrading the former events to their newest versions. In the analysed case, you should map UserWasCreatedEvent to UserWasCreatedVersion2Event when reading from the Event Store. Then, when reading the object, you have to pass only the newest version of the event. It will look like on an example below:
Thanks to this solution, you can handle the newest version in aggregate.
Advantages:
- you don’t change the history,
- you maintain the handler of one version of an event in aggregate,
- you get rid of the redundant code.
Disadvantages:
- you lower efficiency when reading aggregates,
- upcasters need to be maintained which means some additional code,
- you need to rebuild Snapshots,
- no Broadway support.
So, which solution should you choose? It depends on a variety of factors. Personally, I will definitely try to avoid rewriting the Event Store and I would consider it only as a last resort when all the other fails. Upcasting seems to be the most optimal solution, as in domain you don’t have to handle many versions of the same event. In both, reading and writing you have only one version of an event. Also, you can implement Broadway functionalities on your own, knowing that there’s no support from this library. You only have to decorate the existing object of the Event Store or write your own one and then implement the logic responsible for upcasting
Snapshots
The other problem may be caused by a huge amount of events for single entities. Let’s imagine that the vast majority of the key aggregates contains up to 1000 events. In this case, reading the objects would be extremely expensive, especially if you decide to upcast. This problem may occur if you project your model poorly and the event granulation is too big. Also, it may be that you have too many changes which cause too many events. What to do then? In this situation, Snapshots may be helpful. You just need to save the aggregate status after a certain amount of events. When reading an object from the Event Store, it’s enough to get the newest Snapshot and apply only the newest events. On the example below, there’s a presentation of applying the fifth event to Snapshot.
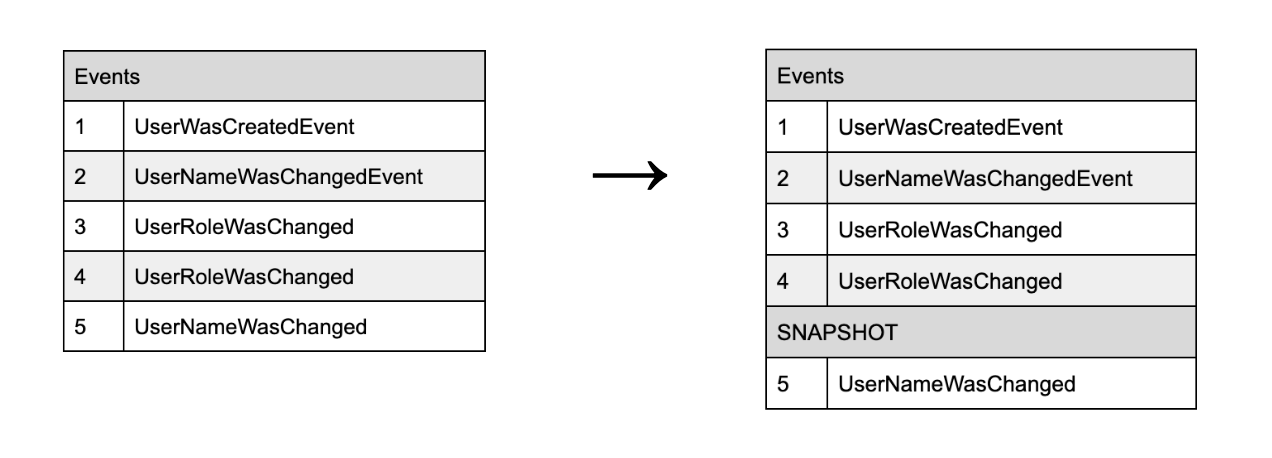
This solution helps you read the objects pretty fast and quite easily, however it also causes additional issues… As I mentioned above, after providing any changes in aggregates, adding a new version of a certain event and using a proper upcaster, you should also rebuild Snapshots to make sure that they correspond with a current status.
Eventual consistency
Building an app which is based on CQRS, you mustn’t forget about the fact that propagating events between the Read Model and the Write Model can take a while. Depending on infrastructure and the amount of data – delay may be different. Eventually, the changes will be applied and the models will be compatible. However, you must be aware of it and also – you should make the Product Owner aware that the situation like this will definitely happen and why is it so.
Also, it may happen that during a breakdown, the system will be available but not necessarily up-to-date. Therefore, another question emerges – what is more important for you: system availability or rather up-to-date data. But it’s a topic for another article.
Be responsible when using the tools
You should remember that CQRS is not an architectural pattern. That’s why you shouldn’t use it in the whole system. You should rather set yourself some limits and make sure you respect them. CQRS can certainly solve some problems, but it also brings a huge complexity to your project. That’s why you should consider in which cases it’s actually good to use it and when you should avoid using it as it would only cause more problems.
Before you decide to implement CQRS in your application and before you try to convince your team or client to do so – make sure you test this solution. It’s good to try it on a smaller project. One of the most important decisions related to a project is the events’ granulation. At the same time, it’s extremely difficult to fix after all. Too much granulation will make some events useless as they’ll have too little information. On the other hand, too big events are pretty expensive when serializing/deserializing. Moreover, upcasting may be problematic, because it will be more complicated. That’s why you need to have experienced but also have some instinct to make sure you do it properly. Believe me, you may get these skills through experience and learning from mistakes.
CQRS and event sourcing – summary
It brings us to the end of this extensive article about CQRS and Event Sourcing implementation in PHP.
Now:
- you know what CQRS, Event Sourcing and Broadway library are and how to use them,
- you are aware of how to implement the Read Model and the Write Model,
- you know what are the most common issues you may face when implementing an app using CQRS and Event Sourcing.

I’ll advise you to invest some time and try this solution to decide whether or not it’s useful for you. You should also brush up on related topics such as event log, domain model, data store, event driven architecture, event processing or temporal queries.
And remember – it’s only worth implementing if you decide that it brings measurable benefits for your project.

