04 September 2018
Simple OCR implementation on Android with Google’s ML Kit


New technologies are evolving rapidly. Some of the newest solutions are gaining popularity every day. Optical Character Recognition (OCR) is nothing new, but perfecting it with machine learning may shed a new light on OCR. It’s obviously a broad subject. Nevertheless, I’ll try to briefly introduce you to the machine learning within OCR implementation on Android. I’ll also present some of its functions, basing on an easily available software called Google Firebase ML Kit.
What is OCR?
Nowadays, almost everything is digital. Books, newspapers, articles – name it. So what can be done to make a written or printed text digitized or even translated? Optical Character Recognition (OCR) comes with the solution. It’s capable of finding the text on the images and making it digital.
Nowadays, almost everything is digital. Books, newspapers, articles – name it. So what can be done to make a written or printed text digitized or even translated? Optical Character Recognition (OCR) comes with the solution. It’s capable of finding the text on the images and making it digital.
Whenever you need to split the expenses between you and your friends – it’s always a problem. Who and how much should pay for pizza or drinks? Now, you can take a photo of a receipt and an application on your smartphone can split the expenses for you. It can even send the reminders about the payment to your friends.
Also, searching for the information about a bus line may be easier. By taking a photo of a bus number or a name of a bus stop, you can get the information about a bus line you need.
Computers are dumb themselves and can’t recognize anything from an image. For them, every picture is just a bunch of pixels, basic information about colours. To help the computer find what you need, we can teach it how to recognize the letters. It’s known as pattern recognition. It can be used for a text that has the same font, size and spacing from the top to the bottom. But what if we have different fonts and sizes throughout the text? To help the computer, detection feature needs to be introduced.
Detection feature or intelligent character recognition (ICR) is used to identify characters’ traits. It searches for letters that meet the specified requirements. For example: if you see two angled lines that meet in a point at the top and there’s a horizontal line between them about halfway down, that’s the letter A.
The majority of OCR software uses a detection feature, rather than pattern recognition, to find the letters on images. Some of them use machine learning to teach the software how to recognize the characteristics of the letters.
See also
OCR implementation on Android
Google Firebase ML Kit is a set of the tools which helps to implement machine learning on Android and iOS – OCR is one of them. It’s relatively easy to start using machine learning. ML Kit has some built-in modules that enable text recognition, face detection, barcode scanning and more. If you’re experienced in neural networks and want to use more sophisticated or specialized ML, you can use custom Tensorflow models.
ML Kit has two versions: on-device and cloud. You’ll find the differences and all the features of both versions here. We’ll focus on the Android on-device version below.
Before we start, we need to create the Firebase project in the Firebase Console. Tutorial can be found here. It requires the knowledge of Kotlin programming language and RxJava2.
Now, let’s add the Firebase ML Kit module in AndroidManifest.xml and gradle dependency.
With this setup we can start implementing our text detector. We need to create FirebaseVisionTextDetector.
Now, we have the instance of Vision detector which is used to detect the text on the images. To do that, we use:
This method takes instance of FirebaseVisionImage as a parameter and produces Task<FirebaseVisionText>. When task is ready, we can grab FirebaseVisionText. It contains the data about the detected text and the bounding boxes of the detected areas.
You can create FirebaseVisionImage from a bitmap, using a method below:
There are other factory methods to create FirebaseVisionImage. We can check them in Firebase documentation. For now, we’ll use a bitmap version.
Below I’ve implemented the full detector class. I’ve used RxJava2 to process input and output of the text detector. I also wrapped Firebase Task<T> class in Flowable to detect the text on RxJava stream.
Full TextDetector class:
Important points in the class above are processImage and observeDetections functions. First one is an input point and the other is an output for our detections which you can listen to.
Now, we need to draw detections on the scanned image. All the bounding boxes come from the FirebaseVisionText object.
FirebaseVisionText contains blocks, lines and elements. Blocks are the largest areas of the text, each block has lines and all the lines have elements.
Knowing this, we can draw all these elements on our input bitmap. To do that, we need to gather all the bounding boxes for each unit and then draw rectangles on a bitmap.
Below, there’s a complete snippet:
Output code will look like this:


Blue border represents the block, green represents the line and white represents the element. Pretty much all the text was found.
Get similar stories with on-point advice you learn from
📬 Be the one who knows “how”. Access the TechKeeper’s Guide — a bi-weekly list of curated stories on technology, leadership, and culture-building read by professionals like you.
Testing the text recognition on receipts
I decided to test three receipts and check how Google’s text recognition will handle them. Each receipt was in different language: Polish, Spanish and German. I’m unable to test languages different than Latin-based, because on-device version doesn’t support them. To test languages like Greek or Russian, the cloud version is required.
The first receipt was in Polish. Below, we can see two images. Text highlighted on the left image shows what have been detected by ML Kit. On the right image there’s a data returned by API, drawn on white background. It seems pretty much the same as on the original image. Of course, there were some issues with formatting. Also some letters weren’t detected or were confused. Besides that, we can see that the results were rather good. I aligned all the lines vertically and adjusted the text size to the boxes, what you can see below. Without these corrections there was much more mess.

The second test was performed on the Spanish receipt. This one was in low resolution (225 x 335px). As we can see, detector found only two blocks on the entire image.
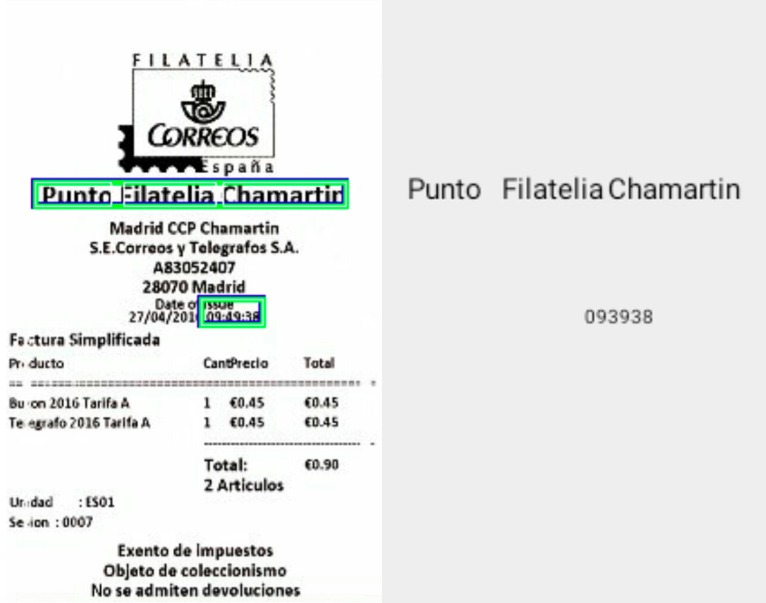
And the last attempt was on the Swiss receipt in German. Detection was almost faultless. Whole text was found, except “e-mail” at the bottom of the receipt. Detector only found last letter of “email” word and assumed it’s 1 (number one).

Simple implementation, simple outcomes
I’ve presented you an overview of OCR basics. I also showed the OCR implementation on Android using Google’s ML Kit. Implementation of ML Kit is rather simple and doesn’t need that much coding.
When using an on-device version, detection is limited to the Latin-based languages. Scanned images must have a decent resolution to get good results. Detector doesn’t recognize some of the letters or confuses them. Also, there are some problems with the text written vertically. To get better results, cloud version, other specialized OCR software or custom Tensorflow model are required.
On-device text recognition can be used to detect keywords or some simple information from larger text rather than extended articles.
As I’ve mentioned earlier, OCR is nothing new at all. But the introduction of machine learning within this technology may significantly improve it. In the nearest future we may witness extended, smart OCR implementation, version 2.0. Who knows?

