04 August 2022
Snowflake overview – why did we choose it for our data warehousing needs?


A data warehouse is the heart of a big modern organization, providing insights into how its systems and users work and acting as a foundation for both short and long-term strategies. Like a heart, it needs your attention and regular checkups. At times, in response to more or less unexpected events, it even needs a procedure to ensure its health. In a recent project, our data warehouse needed just that. Was Snowflake the cure the data warehouse called for? Read the case study and find out.
If you ever worked with a data warehouse, you know just how complex it may get when you get to handle multiple databases and tons of legacy code from a variety of external servers.
That’s also where the story begins.
Background – why did we change our data warehouse solution?
The project in question had been using Amazon Redshift for a while as its primary data warehouse. For the most part, my team considered it sufficient. The problems started when it was decided to migrate a Microsoft SQL server database to the warehouse. The database was dispersed, having been located on multiple servers. In order to access it, we need to go through a bunch of virtual machines. Naturally, each virtual desktop required new credentials.
To make things worse, the aged dev, test, and prod servers were no longer consistent with each other. What you found on the test server might not have been the same as what you got on production.
Suddenly, we got:
- more processes,
- more data,
- and more users.
Our tool was no longer fit for the task at hand. The two main issues were:
- The lack of automatic scalability forced us to resize our resources manually. That took time. Typically, it was just several minutes for a resize, but even that was too much for this particular system.
- Data access management was troublesome. Again, we were forced to generate requests manually every time someone from outside of our team needed some data. And the number of people in need of data kept growing.
The importance of the data warehouse for this specific business was such that we could not sit and repeat: “This is fine”.

The challenge – in search of a perfect fit
We have entered a rather long phase of selecting the best data warehouse for our situation. As you can see, the task was massive. It also had implications for the future of the whole system. We had to take time to analyze our options and choose the best solution for this specific scenario.
We wanted something that meets three criteria:
- It has a customized solution for our particular business case.
- There is a potential for improving the performance of our system.
- It is user-friendly, making it possible for multiple users, including less experienced DevOps people, to use it efficiently.
I believe it was our team leader that first mentioned Snowflake as a possible solution. Following this recommendation, we contacted the Snowflake team and got a demo. That kickstarted a rather lengthy process of determining the best data warehousing provider.
I’m not going to elaborate on this process. The point is that we have chosen Snowflake. In the next sections, you’re going to find out if we made the right decision.
What is Snowflake exactly?
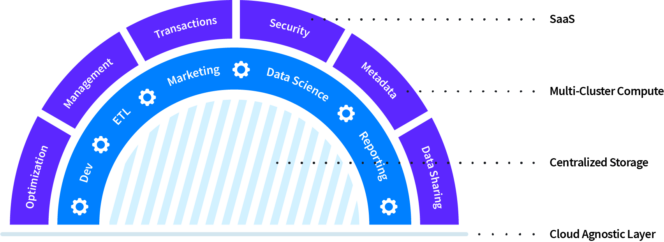
Snowflake is a modern and intelligent database available in the cloud. The Snowflake architecture is a mixture of traditional shared-disk architectures and shared-nothing architectures in a way that offers the simplicity of the former and the performance of the latter.
One look at its page will fill your head with many buzzwords popular in the cloud industry. But the thing is – in the case of Snowflake, they aren’t buzzwords at all. You really do get:
- data sharing,
- zero-copy cloning,
- data marketplace,
- hierarchical data.
What’s more, Snowflake doesn’t set any limits for the number of users or the number of data processes. You will not run out of resources to serve your queries or customers. Sounds good, doesn’t it?
It sure does, but let’s leave the theory behind. What actual problems did Snowflake help solve?
Are you now in the process of shaping your approach to cloud development? Read these mini case studies on AWS, GCP, and serverless!
The solution to data loading
The Redshift code we inherited from the previous team was primarily written in Python, with a touch of Golang. In theory, we could have just taken the existing processes and inserted them into the Snowflake system and be done with it. But that would not give us the improvement in data loading that we were seeking.
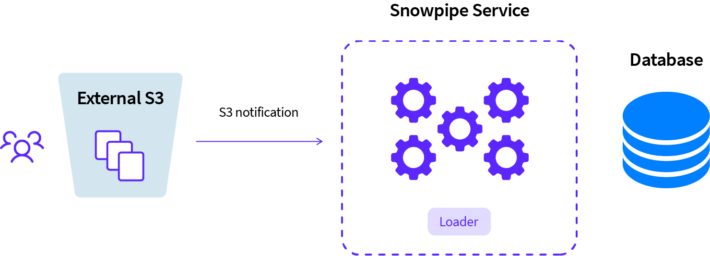
Instead, we chose to use Snowpipe – Snowflake’s original solution to data loading. The configuration was really simple. All we had to do was create a storage integration in the Snowpipe. Once configured using Snowflake’s pipe, it downloaded data stored in our Amazon S3 cloud services layer without any issues.
We can do all that and more using the system’s UI combined with a couple of simple queries. Once this is done, all that remains is to take care of the AWS issue, that is, adding an event to the bucket and making sure it falls into a proper SQS (Amazon Simple Queue Service) using a proper ARN (Amazon Resource Name), eventually triggering the pipeline.
This data loading process happens almost instantaneously. What’s more, Snowflake automatically manages the whole thing, choosing just the right amount of processing power. And it does so efficiently.
Do you want to read even more about data loading using Snowflake? Take a look at Snowflake documentation.
Big selling points of Snowflake
Indeed, Snowflake offered us a fairly simple solution to our main problem. But the tool has many other benefits, which we experienced while working with it.
Below, you’re going to find out what the advertised selling points of Snowflake really translate into in the heat of a project.
Supported file formats
Snowflakes allows you to upload data in a bunch of different formats:
- JSON,
- Avro,
- ORC,
- Parquet,
- XML.
Snowflake loaded the data to our staging environment, which was perfect for our use case. We could choose the data we wanted to move further. We used dbt for data modeling. The processing of data worked well thanks to all-around good support for all of the formats offered by Snowflake.
These formats include:
| Type | Format |
|---|---|
| Structured | Delimited (CSV, TSV, etc.) |
| Semi-structured | JSON |
| Avro | |
| ORC | |
| Parquet | |
| XML |
Here is an example of a Snowflake query that gets value from a given property:
Zero-copy cloning – how does it work?
I was tasked with moving data from the old system to Snowflake. The new implementation had to mimic the behavior of the older process one to one. Otherwise, all the other processes dependent on that one would fail. When I got to it, it turned out that the test data caused some unexpected problems. To work it out, I was to move data from the production to a testing server.
And here comes another big pro of using Snowflake – it provides developers with an easy (and free of extra charge!) way to clone data using the following command:
What does this solution mean for us developers?
For starters, you get instant access to data in the new location without having to pay for it.
But there is more. Let’s say that you need to replace some data on production, but first, you want to test the new data to ensure that there will be no surprises. There is no problem when you already have a mirror server that is consistent with the production environment. When it’s not the case, the chances of doing all this without complications drop significantly. That’s where Snowflake comes to the rescue.
The basic idea is explained in the infographic below:
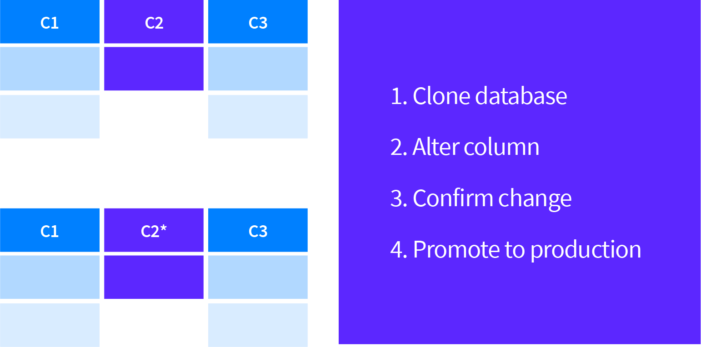
You clone the production database and then send a query to the cloned database. When everything is alright, you can clone it back to production. The data is overwritten and everything works as supposed to. Too easy? That’s how it’s supposed to be.
Data sharing? Don’t worry about data sharing
Snowflake’s data exchange is your own data hub. You have full control over who has access to what and what kind of actions they can perform on the data. It proved very useful in our situation.
We had a whole separate team working on a section of the project. They had access to our database, but the processed that governed were different and custom-made for them. The processed moved data in a given format to an AWS S3 storage. Nothing too complex, but it did generate maintenance costs.
Snowflake solved this problem as well. Using its data sharing capabilities, we could give access to just what we wanted (and nothing more) with just a few clicks.
Marketplace
Another big asset of Snowflake is its Marketplace.
It primarily consists of various sets of data that you can clone to your own data warehouse. You can also clone it for your client, or make it accessible to everyone.
Snowflake’s official website describes it as follows:
“Marketplace gives data scientists, business intelligence and analytics professionals, and everyone who desires data-driven decision-making, access to more than 1100 live and ready-to-query data sets from over 240 third-party data providers and data service providers.”
That’s a lot of data. But is it really that useful? That’s up to you to decide. One thing is for sure – the sheer amount of third-party contributions shows how many companies have already taken interest in Snowflake and how much potential it has for the future.
Visualizing Worksheet Data
Do you like tables, charts, and other data visualizations? If you do, then you will almost definitely come to enjoy Snowsight.
This data visualization tool is quite promising. Depending on your settings, it can visualize just about everything you need. You can use cookies and data derived from this source, visualize engagement and site statistics, audience engagement and site conversions, personalized content and ads according to your settings, or better track outages and protect against spam fraud and abuse.

You can use it to visualize your data (e.g. site statistics to understand user flows and other processes in your application), save it, and make it easily accessible to any users, including non-technical ones.
The marketing department will definitely find it useful, but the devs also ended up using it a lot. It proved adequate for making visualizing our data quality tests in real-time.
What we achieved thanks to Snowflake
At the end of the day, moving our data warehouse to Snowflake proved to be a very good move. It’s not that the solution is inherently superior to Redshift. It just turned out to be a better fit for our project. That’s due to a number of factors:
Our server has become more efficient and scalable
- Snowflake’s unique approach to automatic scaling made it easier for us to use just the right amount of resources. It took more effort to do the same with Redshift, especially when it comes to Microsoft SQL Server.
- Just for test purposes, I tested how long it takes to implement a resize for a fresh Redshift cluster. It’s about 15 minutes. That’s a lot when your system handles big traffic and runs out of resources.
Whether 15 minutes is acceptable or not depends on the nature of your business. We could not afford it. An alternative solution to Snowflake would be to buy a bigger cluster before it is needed. However, in that case, your server costs will go up and you will pay for unused resources.

Our data visualization capacity improved
- The easily shareable data visualizations offered by Snowflake are really useful to us. Since our app calls for quick reaction time, this is a welcome change. Before, we also could get all the data, but it took much time to find and distribute it across the team.
The data is more consistent
- The ability to process data in the JSON format and the confidence that the data we load is the same as the data that ends up in our S3 Bucket are both big pros of using Snowflake. Afterward, all it takes is to send a request to SQL to model your data and you’re all set.
The data is more accessible
- The flexible access options make it easier to distribute just enough access to all the relevant people that they need to complete their tasks. The data is available in real-time.
The setup is simpler
- As a result of the project, we got rid of a bunch of servers, each of which used a different technology for database management, and replaced them all with Snowflake.
- This allowed us to achieve full consistency between all the different environments: Development, Testing, Acceptance, and Production. Naturally, it didn’t happen overnight. Overall, data management became easier, which in turn influenced the quality of data delivered.

How did our DevOps team become one of the biggest of its kind in Poland? Learn about this and more cloud facts!
Not all roses – when is Snowflake NOT the right solution?
As you can see, Snowflake really made a difference for us. But just so you don’t think that it is a perfect solution (there is no such thing), I’m going to go over a couple of cons that I noticed during my experience with this service:
- Snowflake entails the use of cloud providers such as AWS, GCP, or Azure. It means that you are going to be highly dependent on them. In case of a malfunction, you will need to wait for them to fix it on their end and there isn’t a lot you will be able to do about it.
- The Snowflake data cloud is highly scalable, but it doesn’t provide data limits for its computing or storage capacity. When you use the pay-as-you-go model, costs may rack up.
- The service is gaining popularity quite quickly, but the community is not that big yet. When you come across some challenges, you might come to the realization that nobody has ever come across or written about them yet.
These are not dealbreakers, but they definitely prove a point that Snowflake is the optimal solution only for very specific use cases: systems that require great scalability and flexibility, even at the cost of higher costs of use and maintenance.
The Snowflake data platform – lessons learned
And that’s it for our experience with the Snowflake virtual warehouse. I’m leaving you with a couple of thoughts.
- When I look back at the state of our system before the migration, I am really impressed that we managed to pull it all off. There were so many processes, technologies and conflicts, and inconsistencies. But Snowflake made the whole process quite pleasant.
- It gave us the opportunity to rethink our approach to cloud storage and redo many of our data processing workflows. Snowpipe and DBT proved very useful. They made it easier to model and deploy our data, vastly improving our database storage and processing capabilities.
- The experience with Snowflake’s data warehouse made me more interested in data analytics used as part of cloud services, which means that not only did it make our system better, but it made us more passionate about what we do.
And if this isn’t a good reason to always look for a better, more fitting alternative for the tasks at hand, I don’t know what is!

