15 June 2021
Communication in event-driven microservices architecture

Microservices have great potential benefits in scalability and performance. But many still hesitate to implement them. They aren’t entirely mistaken. Microservices can be a great choice but only in specific cases. And communication in event-driven microservices architecture requires special programming patterns to work efficiently. We’re covering all of that today.
Microservice architecture
Have you ever considered microservice architecture as your main choice for an upcoming or existing project? Many of us have heard about microservices as they remain a very popular topic in the IT world. So what’s holding you back from making that decision?
Maybe you simply aren’t sure how to get started with them or what difficulties you might encounter? For sure, one of the crucial aspects of microservices is communication, and we will focus on it.
I hope that throughout the course of this article, I will be able to dispel some myths regarding this topic and when you face this choice again, it will be easier for you to go for microservices (of course, that is, if you really need them).
Before we go into the details of inter-service communication in microservices, let’s quickly define what the microservice architecture actually is and what it looks like.
According to a fairly general definition, it is a way of designing applications as groups of services that we can implement independently of other services.
Benefits? Loosely coupled with separation of concerns
We divide services into groups that correspond to specific business processes. Designing web applications with principles such as loose coupling and decentralized management enables us to reliably deliver even the most complex ones.
More pros include:
- independent deployment,
- agility,
- flexibility,
- scalability,
- cloud-native friendliness,
- improved observability,
- separation of concerns,
- and for those interested, there’s much more in the report below.
In-depth research to understand microservices in 2021. Our State of Microservices report includes statistics and insights from top experts
Types of communication in microservices
We can distinguish two basic types of communication: synchronous and asynchronous.
Synchronous communication
Synchronous communication is a typical example of a request-response one. The calling service waits until it receives a response. The communication is carried over HTTP protocol usually utilizing some kind of REST API. The whole asynchronous communication is rather straightforward as HTTP is a well-known text protocol, which also makes predicting request results easy.
And when it comes to the results, we get the data “immediately”. One of the downsides is that the application is blocked until we receive the response. And it makes it even more difficult if one request requires multiple sub-requests spanned over multiple services. If one of the services fails during this call chain, the whole request may be treated as invalid.
Asynchronous communication
Asynchronous communication is based on the concept of events and messages. The caller service emits an event and processes subsequent requests without waiting for the response. Here, we can use one of the many event brokers such as: Apache Kafka, Redis Pub/Sub or RabbitMQ.
Some noticeable gains of going async are:
- loosened service coupling,
- improved application responsiveness,
- easier failure handling.
But everything comes at a price – we are relying heavily on an event broker and communication becomes complicated. Not to mention that bug tracking in this type of system can be challenging.
Now we know basic communication types. What’s next?
Let’s assume that we decided to split a monolith application. We can quickly notice that things that weren’t a problem before have become a little more complicated. One obvious thing would be data retrieval.

After we split our app into various services, each of them can contain their own database. Unlike in the monolith app, we can’t easily join data between tables of a single database. Now we need to fetch bits of data by ourselves from various sources. Luckily for us, we can use programming patterns to make it a lot easier. An especially useful one in this case would be API Composition.
Learn more about design patterns in microservices.
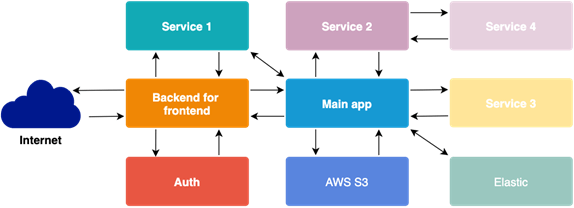
API Composition
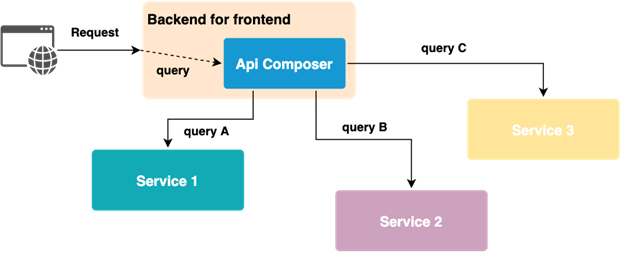
This pattern allows us to combine responses from different services. Responsibility for joining data falls on one specific service. Usually, it is the backend for frontend service or gateway. How does it work?
The API composer queries individual services and combines data to be returned. It is useful if we require a response immediately. For example, any kind of search endpoint would be a perfect candidate for this pattern.
Now that we know what communication types we can use and how to fetch data from various services, we can take a moment to think about how to communicate microservices together to fulfill business logic. We do not need to ponder a solution as one of the options for us is the orchestration pattern.
Orchestration
In this pattern (which is an extension of the API composition), we have a central point that manages interactions between services. There is one service delegated for this purpose with knowledge about all other services in the system.
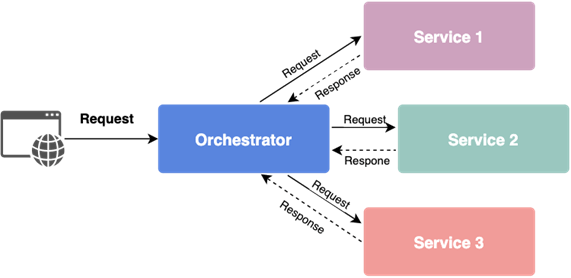
The orchestrator queries specific services in a given order to complete the business logic. It is especially useful if we require some data from one service in another. Communication is simple and mostly synchronous. The problem here is the susceptibility to failures – if one service fails, others will also stop working. Additionally, the centralization of knowledge creates strong dependencies, which can lead to a distributed monolith. That is something that we would like to avoid to preserve flexibility of our application.
Knowing two previous solutions, we want to put emphasis on decentralized management, loose coupling, and flexibility. To achieve that, we can (actually, we should!) use asynchronous, event-based microservices architecture communication.
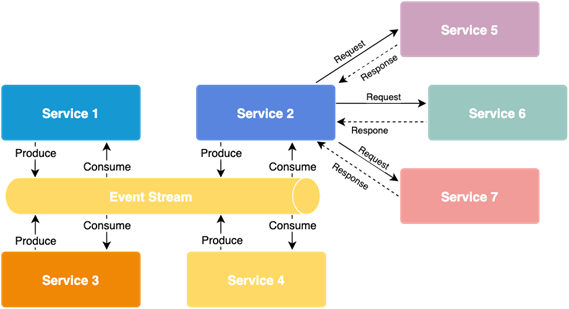
Publish/subscribe pattern (with a broker)
Moving from synchronous to asynchronous communication, we should get familiar with the publish/subscribe pattern. It enables the exchange of messages between publishing services and subscribers of specific messages on the event/message bus.
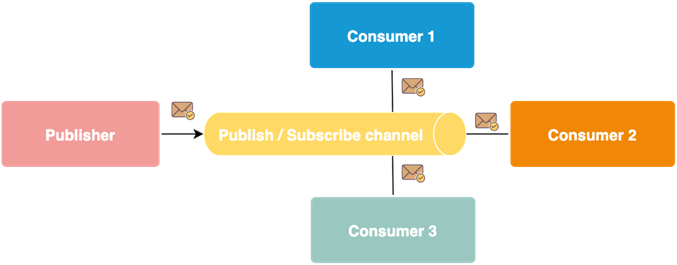
The sender does not know how many recipients there are; and the so-called event/message broker deals with the delivery of messages over the bus to specific subscribers. Additionally, we gain the ability to send events to many recipients at the same time.
So we switched to event-based communication, and that is great, but now we need to rethink the way we coordinate operations.
Choreography
One of the popular patterns addressing problems of distributed logic execution is called choreography. In this scenario, all services listen on the event bus only for specified messages. Upon receiving such a message, they run internal processes to handle them. At the end of the processing, the service can broadcast new events back to the bus.
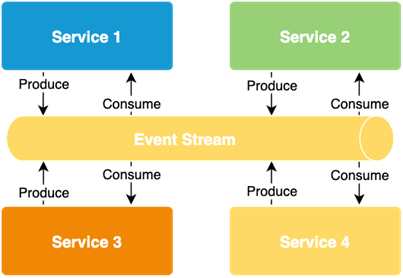
In this configuration, we ditched the central point of process management, focusing on better service isolation, providing greater flexibility for changes, and reducing the risk of failure of the entire system.
And when it comes to failures in the system, what can we do to ensure data consistency in the application?
We can implement error-proof transactions that span over multiple services. To achieve that, we can use choreography-based sagas.
Sagas
A saga is a sequence of local transactions performed by specific services in order to complete a certain business logic. The first transaction in the saga is initiated by an external request sent to the system, and each subsequent step is triggered by an event published after the completion of the previous local transaction.
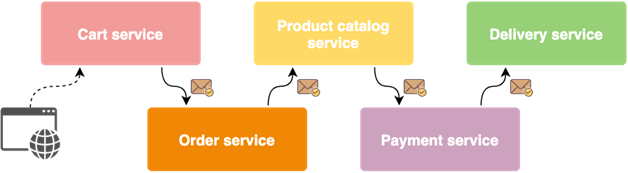
One of the unique features of the sagas is the ability to execute compensation transactions, which allow us to undo changes made by previously executed local transactions. This is the key feature that allows us to ensure data consistency in the microservices architecture.
What other challenges can we face during development and how can we handle them? Continuing the topic of errors in the system, let’s focus for a bit on transient system faults. These types of errors are quite common — especially for large cloud-based applications. For example, some services don’t respond, or we have connection problems.
The retry pattern
To cope with that type of problems, we could use probably the most widely used pattern called retry.
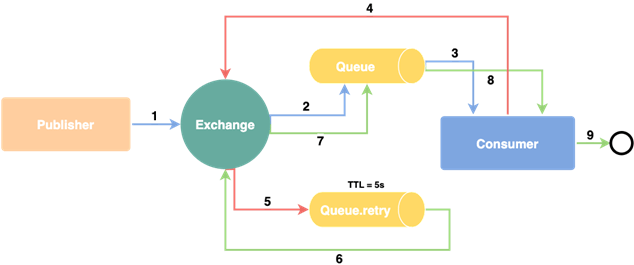
Retries are designed to deal with situations where, for a short period of time, a system component is down or becomes unresponsive. After detecting a failure – e.g. a time out – it can automatically retry the operation.
And how to deal with non-transient system failures?
The key thing regarding these types of issues is to limit the impact of such a failure on our entire application.
To handle that case, we can use the circuit breaker pattern.
Circuit breaker
Circuit breaker allows us to react to errors and gives an immediate response to a failure. This happens without the need to wait for the propagation of information about a failure itself or further timeouts. The easiest way to implement this pattern is as a proxy for a specific functionality.
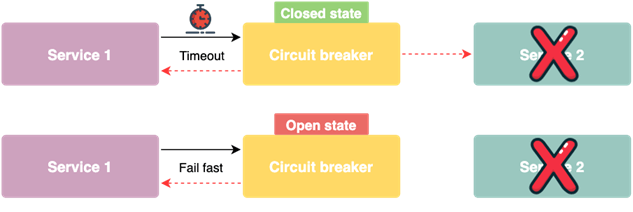
The circuit breaker monitors the number of unsuccessful calls and, after exceeding a certain limit, it will cut off the possibility of making subsequent ones. When the circuit breaker opens, it will immediately return the information about the failure. In the world of events, we can react to the number of messages in the queue, the number of retired events, or the rejected ones.
Tracking ID
Along with the change of architecture from a monolith to a microservices-based one, the way of collecting important metrics and logs changes. Information about errors is scattered throughout the entire system and asynchronous communication makes it even more difficult to analyze.

However, we can get by with the help of distributed tracing. Using the tracking ID added to all events related to the execution of a specific business process, we can easily monitor data flow in the system. We usually generate this unique tracking ID somewhere at the entry point of our application successively adding it to all events emitted through the business logic handling cycle.
Now, when we have logs from all of our microservices that are stored with this extra piece of information, we can easily extract the data we want. We just need to filter records with specific tracking ID and order them using timestamps. Creating combined logs was always a tedious work. However, with the help of the tracking ID assembling those files becomes fairly easy.
Event-driven microservices architecture – summary
Just like any solution, event-based communication has its advantages and disadvantages. First of all, it is non-blocking and asynchronous. It allows us to greatly loosen dependencies in our system, which also means that scalability should be easier. Not to mention that as a nice bonus we get a possibility to notify many subsystems simultaneously.
So what about the parts where it does not shine so much? Communication becomes a little bit more difficult to track (especially if we do not implement distributed tracking) and we are somewhat dependent on the event broker.
Lastly, we need to keep in mind that if we decide to give the event-based inter-communication a go, we should allocate some more time at the beginning of a project. Why? Because we need to implement all best practices and failover solutions which will make our life easier in the long run.
But trying to answer probably the most important question: which type of communication should you choose?
It largely depends on the problem you have to solve. There are situations in which a given type of communication will work better than others.

Fortunately, we have the option of using both types of communication in our application. So for example, the search functionality within our app could be done synchronously and order processing asynchronously in the background.
Bonus: Choreography-Orchestration Hybrid
🧮 Try this test to determine your company’s observability mastery
Event-driven microservices generate tons of data. Are you sure you can make sense of it? When you invest in observability, you can do more, improving any metric and cutting cloud costs. Find out where you stand.

