09 December 2021
Share AWS infrastructure attributes from Terraform to Serverless


Sure, you can manage AWS cloud components just with Serverless. But why would you when Terraform was designed to do it better? By default, they don’t integrate. Follow this guide to learn how to bridge Serverless and Terraform in 3 ways to handle infrastructure work with greater efficiency.
Dear cloud providers, what are Serverless and Terraform good for?
Terraform is an “infrastructure as a code” tool used to manage the lifecycle of cloud components. You write code that defines the cloud infrastructure, and then Terraform maps it to actual resources like databases, virtual networks, event buses, and so on.
The Serverless Framework is a command-line tool that can handle cloud infrastructure just like Terraform but rather serves as a place where you create code. After the code’s deployment, serverless interacts with cloud components to execute business logic. It’s not without downsides, though.
Separating dependencies
Imagine having multiple applications where all of them need to interact with cloud components to do their job. What is more, each of them sometimes may need to change some part of the infrastructure.
Let’s say you have cloud component definitions linked to application A. Now, whenever application B, C, or D needs to change the cloud infrastructure, you’d have to make changes to application A.
It is really inconvenient and completely against the single responsibility principle.
The solution here is to create a separate entity that will keep only the cloud infrastructure definition. It is way better to have it written down in a tool for this very purpose — like Terraform.
Which tool is better for handling state changes?
Since Terraform works as “infrastructure as a code”, it can create an execution plan before we confirm changes. When you’re unsure what will happen after you deploy the infrastructure definition, you can ask Terraform to simulate changes.
Unfortunately, the Serverless Framework doesn’t support this mechanism out of the box. For you to have it, it would require a workaround. Let’s go for a clean solution — let me show you how to combine both tools. Of all the cloud platforms, I’m using AWS as I’m trained in it.

Why fusing Terraform and Serverless is a problem
Let’s say you have an application written on the Serverless Framework where a single lambda has to be executed every time a record is added to DynamoDB. It could look something like this.
Configuration for the Serverless Framework application
Dummy handler
I used CloudFormation’s Fn::GetAtt function to tell the lambda which DynamoDB stream it should subscribe to. The function returns a value of an attribute StreamArn from the resource ExampleTable.
Run serverless deploy in a system console and go to AWS console -> Lambda -> Functions -> blog-post-dev-hello. See that our lambda was created successfully and subscribes to the DynamoDB stream.
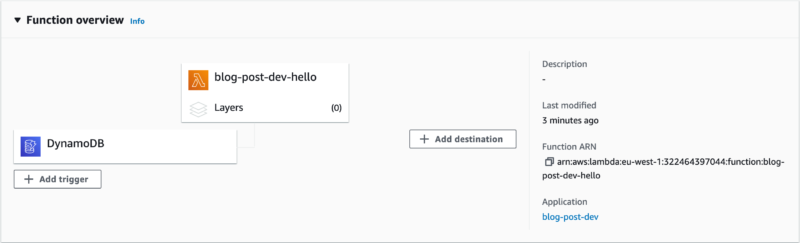
The Serverless Framework was able to resolve Fn::GetAtt: [ExampleTable, StreamArn] without any problems because we wrote the cloud components and the function in the same application.
Now, let’s move our DynamoDB definition to the Terraform application. First, we will delete our current application to prevent later conflicts by executing serverless remove. Then we create a new Terraform application with one file.
But what about our Serverless Framework application?
As you can see, we lost the logical name of the ExampleTable and we cannot use Fn::GetAtt at all. What can we do?

🎦 Learn cloud best practices from 2 CTOs
Watch an event that sets expectations vs reality of cloud use.
You’ll learn to choose the right cloud services and when to optimize architecture to maximize results
Hosted by two veterans — our CTO Marek Gajda and Michał Smoliński, CTO of Radpoint, who built cloud-powered products able to service millions of customers.
April 12th, at 3:00PM CET
Free to join
The dirty way: use hardcoded values
The simplest solution is to hardcode DynamoDB stream ARN. So! Deploy your infrastructure. In your Terraform application, execute terraform init and terraform apply. Now you can go to the AWS console -> DynamoDB -> Tables -> example_table -> Exports and streams where you will find our DynamoDB stream ARN.
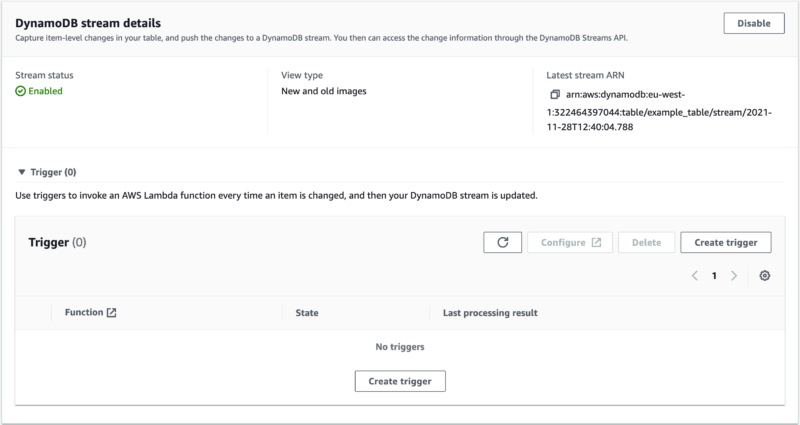
Let’s copy this value and paste it into serverless.yml.
After that, we can deploy the Serverless Framework application with serverless deploy to see the lambda once again subscribes to the DynamoDB stream.

But hold up! We had to execute a lot of additional steps to get the same solution that Serverless Framework offers. Is there a better way to do this?
💡 AWS Cloud for life? These tutorials are for you.
The standard way: work with the Systems Manager Parameter Store
A simpler solution for auto-injecting DynamoDB stream ARN — just like the Serverless Framework does it — is to make use of AWS’ Systems Manager Parameter Store. This service is a simple container with a purpose to store configuration data of your applications. Let’s make use of it!
Add the following code to the Terraform application.
I defined there a new Parameter Store named /blog-post/example-table-stream-arn and the value of the DynamoDB stream ARN as aws_dynamodb_table.this.stream_arn. Let’s look at how I built that value.
aws_dynamodb_table is a type of resource, this is a name of resource, and stream_arn is one of many attributes that this resource exposes. The whole list of these attributes can be found in Terraform’s documentation.
Ok, now that you know what was added, run a deploy with terraform apply. Check if the resource was created by going to the AWS console -> Systems Manager -> Parameter Store -> /blog-post/example-table-stream-arn.
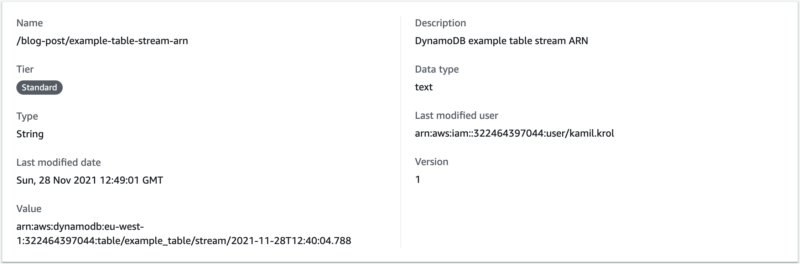
Now, you have to tell the Serverless Framework application how to fetch this data. Serverless provides a series of special variables that are resolved to various values after deployment. One of those variables references the System Manager Parameter Store: ${ssm:NAME_OF_PARAMETER_STORE}
Add the syntax to the Serverless Framework application.
Deploy the application with serverless deploy and see that the lambda function successfully subscribed to DynamoDB stream once again.

Nice! You now know how to solve the problem using the System Manager Parameter Store. But, surprise, there’s another approach you can use! Let’s see a different scenario.
🧠 Grow in skills from verified guides and tutorials
Get better at your game with the TechKeeper’s Guide — a bi-weekly list of curated stories on technology, leadership, and culture-building read by professionals like you.
The exotic way: connecting through AWS CloudFormation Outputs
Imagine you have to declare the infrastructure using a native CloudFormation template. The template is exactly the same one used to declare the infrastructure in the Serverless Framework.
Because of the CloudFormation template’s limitations, you lose access to resource attributes. You now can’t use resource.resource_name.resource_attribute to fetch the stream ARN. Shoo the problem away by using CloudFormation Outputs.
The Outputs is an optional section in CloudFormation templates where you can declare values to be used as cross-stack references. This means you can select which attributes of our infrastructure we want to be easily fetchable.
Adding DynamoDB stream ARN to the Outputs section looks like this.
Now, remove the current Terraform application to prevent a race condition between creating a new database and removing the old one. Run terraform destroy. Then, you can safely deploy our beauty with terraform apply.
Now make the reference to the CloudFormation Outputs variable in the Serverless Framework application. cf:STACK_NAME.OUTPUT_KEY is the syntax for this. In our case, this should look like this.
Deploy it with serverless deploy, and voilà, the lambda function once again subscribes to the DynamoDB stream.

💡 Spotlight on cloud-native architecture
Remember the 3 ways
You might find other approaches to connecting your serverless applications to Terraform. Note that the bridge between them can be also made with other public cloud providers like Azure or GCP.
During the development of a spaceship-big project based on AWS, I relied on three ways for connecting serverless and terraform that you learned from the tutorial:
- Hardcoding the DynamoDB stream ARN
- Fetching data from AWS’ Systems Manager Parameter Store
- Connecting through CloudFormation Outputs to the Serverless Framework
I hope they will serve you as good as they served me. Make good use of them and good luck : )
Is serverless computing the future?
For me, it’s just another tool in the arsenal. No management of physical servers really lets a team deliver impressive value to a client in a few sprints. That and reduced cloud costs — when the set up is right — makes the serverless framework a launch pad for many short-deadline business projects that are brought to The Software House.
Then, if you let your observability team close one eye, you can burn up all the budget overnight. I recommend a story from a fellow developer about how cash-eating Serverless made him eventually switch to Elixir.
What type of serverless apps have you worked on?
- An internal CRM for The Software House’s project management
Built with: lamdas, DynamoDB data storage, and step functions.
When we enter a partnership with a new client, we create the project within the app and assign participants to it. Then, the software creates a specific Slack channel, adds people to it, and sets up a Google Drive folder among other things. I enjoyed focusing only on the code without worrying about the machinery it turns on.
- A digital banking platform
Built with: lambdas, api gateway, cogito, DynamoDB, SNS, SES, and EventBridge
It is a monumental project with multiple, interconnected domains where one holds user information and another manges their finances. The domain I worked on was responsible for connecting all the other ones to a user panel, which was a joyful puzzle to work with.
How can I choose a sure cloud provider for the next project?
Since you’re reading this, I assume your department chose AWS as the cloud services provider. Rethink the epic possibilities that AWS Lambda gives you before considering a switch. Master automatic scaling and you won’t live without it as a Dev.
For your team to be dissatisfied with Amazon Web Services, you probably have either integration or cost optimization issues which you won’t avoid with other cloud vendors. Dealing with them is a job for your CTO or a Cloud Engineering Consultant — and there’s no shame in relying on one.
It’s best to build on the cloud know-how your colleagues have. If your public cloud provider is Azure, stick with it. GCP? Sure. A knowledge transition could take you even 12 months (training + experience), so deal with the issues at hand with some extra help.
Is it true that serverless architecture can be problematic to debug?
I think so.
- You can’t debug complex apps as there’s no option to run cloud services locally
- Serverless communicates through events where any part has an asynchronous connection with another on
For these two reasons, it’s tough to track what happens when we trigger an action. Assume you have 4 components. 1, 2, and 3 were completed successfully. No. 4 failed. You have to debug backward, starting from 4. If you implemented it correctly, you move to 3 and repeat, etc. For me, reading logs saved me nearly every time.

