19 August 2021
Spent 6+ months with AWS AppSync — here's if it's worth it


My team and I have been developing a web/mobile application for a Dutch bank. Under the hood, we prepared an efficient API that contacts multiple other systems, stores its own data, and processes its own logic. We went with AWS AppSync to create a GraphQL API that works with other AWS tools. Still, we got hit with many gotchas on the way, which you’ll be able to spot and counter soon enough.
What is AWS AppSync?
AWS engineers say AppSync is a “robust, scalable GraphQL interface”. They use these buzzwords to describe a mechanism that can combine data stores into a GraphQL API. The input of whatever you connect to it ends up as data in a GraphQL representation — much like whatever you put in a mincer ends up as, well, minced food. AWS APPSync automatically scales the GraphQL API to meet the volume of API requests.
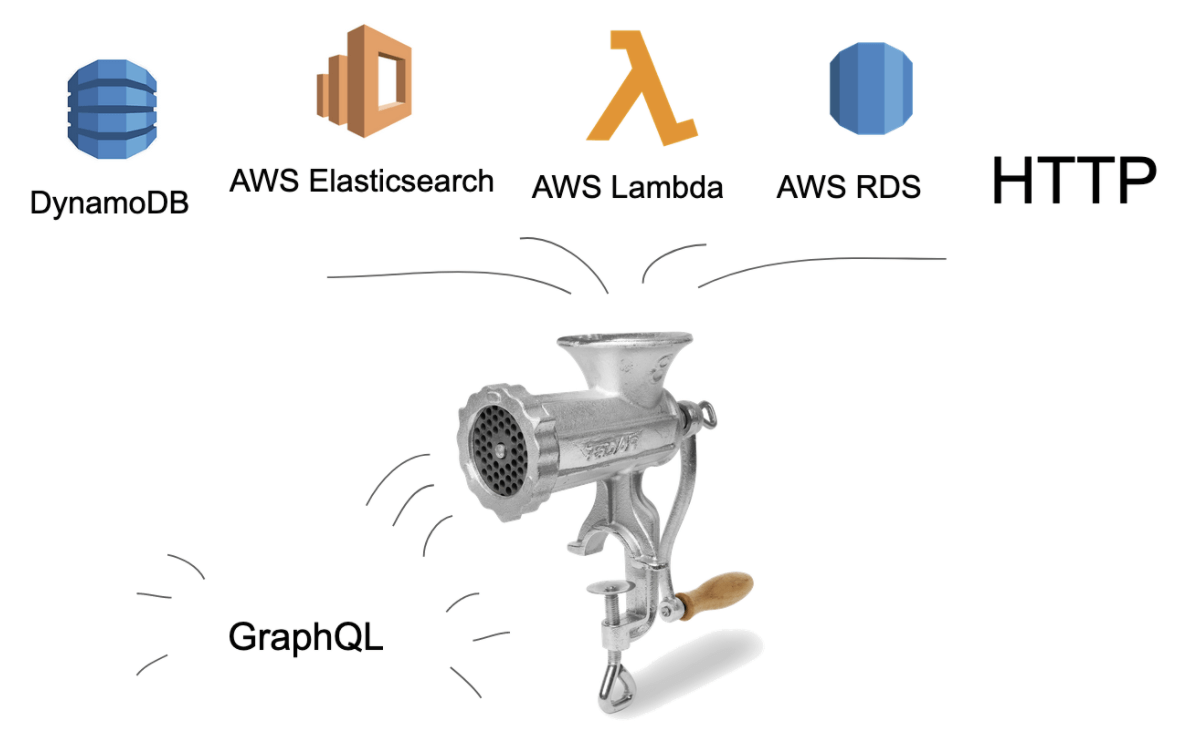
The multiple data sources you can throw into this out-of-the-box mincer can include input from other Amazon Web Services like AWS databases (DynamoDB, RDS, Elasticsearch) and Lambdas added to existing HTTP APIs. Be sure to look at the official AWS SDK resources.
What is GraphQL used for?
If you’re already familiar with this communication protocol, feel free to skip this section. Unless you want to miss a couple of excellent jokes.
A strictly defined schema
GraphQL is a text-based communication protocol made by Facebook and nowadays is maintained by the GraphQL Foundation. You might say your browser uses GraphQL when exchanging data with a server.
It’s not that different from its predecessors. Just like SOAP is a self-describing, XML-based communication standard, GraphQL also has a specified way of describing the contents of a flexible API.
It’s called the Introspection Query, and it offers a schema of all implemented operations along with their data format.
Queries, Mutations, and Subscriptions
Software developers were eager to abandon SOAP in favor of REST which, by definition, doesn’t enforce a specific standard.
REST defines a convention to be implemented on top of the available HTTP methods. Knowing what GET, PUT, POST, or DELETE should be used for, you can interact with an API even if it doesn’t offer any formal way to define its endpoint or format.
Queries, Mutations, and Subscriptions are the equivalents of this limited set of HTTP methods for GraphQL. They read, update and transfer real time information, respectively.
As you state the name of the operation inside of the GraphQL query, your API only needs one GraphQL endpoint.
Read exactly the data you need
One feature makes GraphQL superior to other text-based communication languages picked by whimsical developers who juggle new technologies.
What makes GraphQL special is a built-in function to pick which data it loads from an API request or what gets sent in.
If you created an application for your favorite restaurant chain, you might want to only display the names of meals on the menu and their full descriptions while in the detailed view. To avoid exchanging unnecessary data with a REST API, you’d have to provide two separate API endpoints or resort to custom techniques such as data projections.
With GraphQL, you don’t need to implement several queries to establish data synchronization with many levels of detail.
The standard version provides a query language in which the developer defines what app data the system needs, omitting any overhead.
How does AppSync work?
Schema, Resolvers, and Data Sources
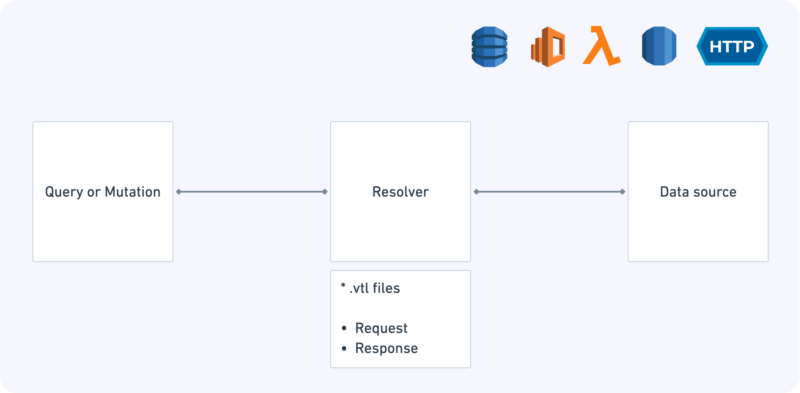
How do you make AppSync turn your data into a GraphQL representation? First off, AppSync needs a GraphQL Schema definition as a base for the Introspection Query.
For each operation — Query, Mutation, or Subscription — we then need to attach a Resolver that maps it to an appropriate data source. A data source may be any of the following:
- DynamoDB table
- AWS RDS database
- AWS ElasticSearch query
- AWS Lambda functions
- An existing API operating over the HTTP protocol
A Resolver is in fact a pair of text files, written in the ancient Velocity Template language (wasn’t invented for this purpose at all). It includes a request and a response mapper.
The request mapper instructs AppSync where to search data queried by the client. The response mapper then defines how to structure the data so that the response conforms to the schema served by the API.
🎦 Learn cloud best practices from 2 CTOs
Watch an event that sets expectations vs reality of cloud use.
You’ll learn to choose the right cloud services and when to optimize architecture to maximize results
Hosted by two veterans — our CTO Marek Gajda and Michał Smoliński, CTO of Radpoint, who built cloud-powered products able to service millions of customers.
April 12th, at 3:00PM CET
Free to join
Direct Lambda resolvers
For Lambda functions, mapping data sources isn’t always necessary. You can omit it and you’ll have the so-called Direct Lambda Resolver. After all, you can transform the data in the Lambda code in any way you want.
Pipeline resolvers
What’s interesting, Resolvers can be combined into pipelines. This lets you split the logic into separate and reusable pieces of code.
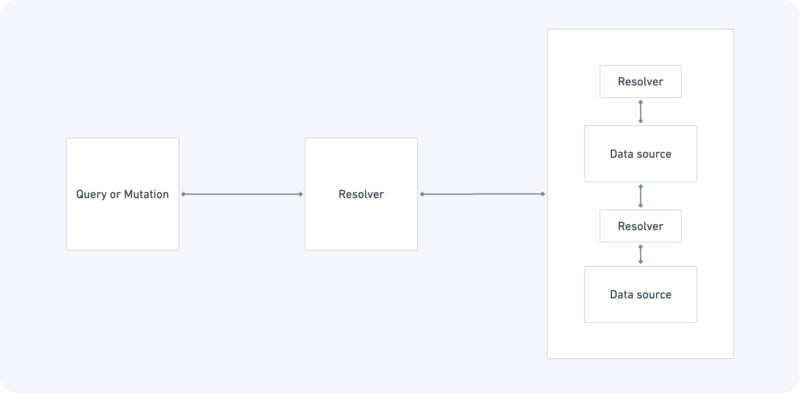
Field-level resolvers
Another trick AppSync can do with Resolvers is connecting a data source to a data field instead of connecting it to a whole query. You might keep your restaurant’s menu in SQL databases for local data access and have the descriptions of each meal fetched from your favorite cooking recipe portal.
👩🏼🏫 We heard you want to be a better developer
… so we prepared a bi-weekly newsletter with detailed programming tutorials and the freshest updates on modern development of any mobile or web application.
Give it a try and join 500+ ambitious readers today.
Authorization in AppSync
Multiple concurrent authentication modes
There are several ways in which you can ensure fine grained access control for your API:
- API key
- AWS IAM
- OpenId Connect
- AWS Lambda
- AWS Cognito
An API key is the simplest and most basic way of securing your API.
It’s not possible to create a GraphQL API that’s wide open to the public with AWS AppSync. At a minimum, that requires an API Key to serve the clients’ requests.
It’s also possible to grant access to your API to specific AWS IAM users, groups, or roles. You can also use other authorization methods such as an OpenId provider or custom Lambda logic.
However, what you will probably choose in the classic user-password scenario is AWS Cognito, which is suitable for web applications that require users’ sign-in and serve user-specific data.
One global authorization method to rule them all
It’s possible to combine several authorization methods for one API.
The rule is that one of the methods is set as the default one, and it applies to any Query, Mutation, or Subscription unless stated otherwise. Any additional authorization method needs an explicit Query-level declaration.
When to use AWS AppSync
Clicks with Backend for Frontend
For our web application that serves user-specific data from multiple sources, AppSync was a perfect foundation for Backend for Frontend.
You can choose AppSync, too, if you’re building a distributed system with multiple domains where data is presented to a client application.
When you only need parts of the data in turns
Data might be costly in terms of money and time. Some external data sources respond with a considerable delay, so you wouldn’t want to query them unless it’s necessary.
The “pick and choose” feature of GraphQL’s query language is exactly what serves this need. You can only contact an external API (or database; or run heavy logic) if the client application requests a specific field.
For our imaginary restaurant application, the meals’ descriptions can be read from a database, if the user enters the detailed view. In all other cases, the query only provides the names of the meals.
You can achieve this either with configuration — attaching a resolver to a specific field instead of the entire operation — or programmatically with the Lambda attached as a data source.
AppSync can provide your Lambda with a set of fields selected by the client as an input argument. In the Lambda code, you can see what fields the client requested and fetch data from another source if you wish to.
If you need mixed authorization methods
AppSync’s out-of-the-box authorization methods should be of use to you, if you can set one of them as default and name all operations that should make an exception.
AppSync gotchas to watch out for
There are a couple of scenarios you won’t complete with AWS AppSync. There are a few workarounds, though.
No public introspection query
If you often expose GraphQL introspection query in public, I have bad news for you. AppSync can’t do that.
AppSync secures an introspection query with the default authorization method. If it’s AWS Cognito, you can query your API for its schema only with a valid access token.
This includes a scenario where a front-end developer wants to generate their API-client code based on the API schema.
Luckily, you can beat this limitation by copying your AppSync API to create its “evil twin brother”.
As long as you keep the two API’ Schemas in sync (e.g. using an Infrastructure-as-code solution like the Serverless Framework), you can keep a separate GraphQL API secured by the simplest API-Key method and a Schema attached with no logic. Its only purpose would be to serve the introspection query. All other usages will throw an AppSync-specific error.
Unstable API keys
You can only generate AppSync’s API key and update its validity date. You can’t set it to a given value as with API Gateway.
This may not sound like an obstacle, but remember that if you recreate your AWS application, the API key will be different.
That might happen after an issue with your Infrastructure-as-a Code. Take my word for it. Those who manage client applications connected to your API won’t be too happy.
You can deal with this by employing a common solution for the API and the client applications that use the API key as one source. AWS Parameter Store or the Secret Manager can do that.
Velocity Templates
Scroll back to the example code to know what’s wrong with Velocity Templates. It’s a templating language that’s almost never used.
You’re unlikely to work with it anywhere else unless you’re maintaining Java-based web applications from the beginning of the 21st century. Velocity Templates are hard to test and powerful enough to ruin your application’s logic.
Use them wisely. Don’t implement too much logic with them except the necessary error handling and maybe some common initialization.
Avoid preparing separate *.vtl files for different data sources. It’s better to omit the VTLs at all and use Direct Lambda Resolvers when resolving your data with a Lambda function.
No Oauth support in HTTP data source
HTTP API endpoints are named as one of the built-in data sources, but they’re not too powerful.
You can configure them in your resolvers’ Velocity Template code to set the required headers or parameters, but there’s no straightforward way to handle authentication.
If the HTTP endpoint you use is not a publicly open API, you must get your hands dirty in coding and querying the API endpoints from within a Llambda function. I mean — a Lambda function. My damn pun-oriented brain.

So is it worth using or not?
Yes, it served our needs here at The Software House, even if it caused some frustration along the way. We’ve been able to expose an elegant, logically organized GraphQL API, combining data from different domains.
Just like with other tools and frameworks, it’s not a quick fix.
AWS AppSync is not for you if your mobile and web applications are outside of the AWS ecosystem. In this case, consider other managed GraphQL engines:
- Apollo Server (open source; a managed version)
- Prisma (open source; a managed version)
- Hasura (open source; PostgreSQL-based)

