06 May 2024
Machine translation. An AI-based solution cut translation costs by 99%



Contents:
Artificial intelligence works wonders for your budget IF implemented appropriately. Human translators are overwhelmed with more complex tasks, and machine language translation partially relieves them. Our partner in the media industry reduced their translation costs by 99% with our Lambda-based solution. Exactly, down from $200 to $1.95 to generate one report with 4k articles!
Business problem – accurate translation
The project emerged from a partner from media industy. The publisher wanted to translate a substantial volume of articles into English, each containing approximately 4,000 characters. Given the large number of texts involved, the solution could operate asynchronously, so there is no need for real-time responsiveness.
We’ve been conducting diverse text analyses for the client, including sentiment analysis, name extraction, classification, and gender analysis. We employed various tools and external services like TextRazor, SpanMarker, etc.
While these tools were effective in English, some texts we needed to analyze were in multiple languages. Consequently, we had to translate them before analyzing English texts.
The main challenge involved ensuring accurate translations from various languages to English and preserving the text’s original meaning.
However, measuring translation accuracy took a lot of work due to the many languages involved. Given the expected large volume of texts, the client anticipated potential high costs in the foreseeable future. Their initial suggestions were leveraging Large Language Models (LLMs) and external translation services.
Our task was to identify the optimal solution, prioritizing cost reduction, as processing speed was not a top priority due to asynchronous operations.
The verification methods included reading texts and relying on metrics provided by the authors of various solutions. One such metric is BLEU. It gives a general overview of the quality of the translated text, comparable to human judgment. Unfortunately, this metric is not perfect because the score strictly depends on the fact that translated language consists of word boundaries. So, it doesn’t work for all the cases.
Read more on this project:
Research & development. Initial ideas that didn’t work
Bloom LLM
Initially, the client suggested testing the Bloom LLM model due to our experience with various LLMs. However, it required one of the most expensive EC2 instances, which ideally should run and shut down after completing the task. The translations were not highly accurate because of hallucinations (common in LLM models, as they aren’t designed for a perfect translation process).
Exploring AWS SageMaker, we identified Batch Transform as a promising solution, but the API wasn’t mature enough and demanded time-consuming development effort.
Natural Language Processing
Recognizing the vast landscape of LLMs, we sought a better alternative. Our architect discovered the University of Helsinki’s Language Technology Research Group, specializing in NLP for morphologically rich languages. They offered over 1400 models at Hugging Face, providing a potential solution to our translation challenges.
![]()
Upon discovering the lightweight translation models (around 300 MB each), we immediately considered running them on AWS Lambda (at TSH, we’re serverless architecture enthusiasts). This approach would substantially reduce costs.
External translation providers
Following extensive market research, we compared popular machine translation services and their pricing models. Initially, we explored:
- AWS Translate,
- DeepL,
- Google Translate,
- Azure AI Translator,
- ModernMT,
- IBM Translator.
All aforementioned providers’ pricing depended on the number of characters in the text. So, we ran a cost simulation vs accuracy.
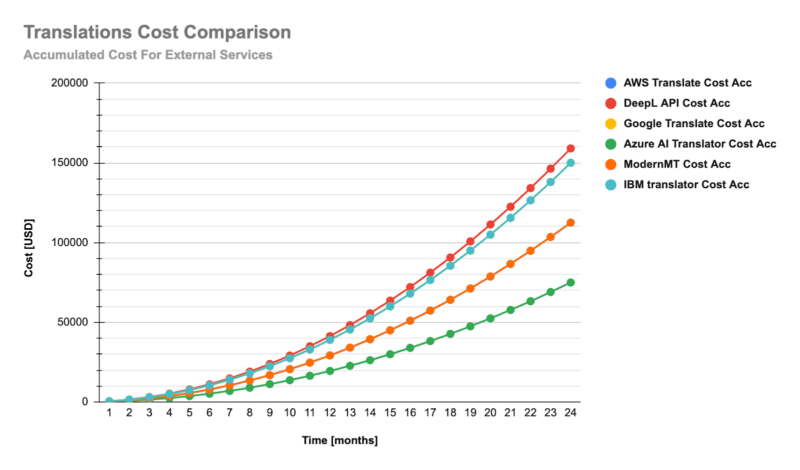
We then projected monthly costs for the next two years, factoring in newly registered publishers, the number of articles to translate, and their average length. The charts highlighted a significant cost spike at the end of the two years, reaching around $100,000 when using external services!
Shockingly, the machine translation module would be more expensive than the overall application expenses! That was unacceptable for the business (and rightfully so), so we sought more cost-effective alternatives.
Testing new tools
We encountered several new tools during our exploration, and for testing purposes, we selected the following:
- SeamlessM4T
Tested using the SeamlessCommunication package and a Spacy tokenizer.
- NLLB
Older architecture compared to SeamlessM4T with limits to noncommercial usage.
- M2M100
Tested using EasyNMT.
- MBart50
Tested using EasyNMT.
- OpusMT
Tested using EasyNMT.
We delved deeper into their characteristics, considering factors such as organization, speech support, available languages, licensing, and whether it’s a single model.
| Solution | Organization | Source | Speech support | Languages | Single model | License | Commercial |
| SeamlessM4T | Meta | Link | Yes | ~100 | Yes | CC-BY-NC 4.0 | No |
| NLLB | Meta | Link | No | ~200 | Yes | CC-BY-NC 4.0 | No |
| M2M100 | Meta | Link | No | ~100 | Yes | MIT | Yes |
| MBart50 | Meta | Link | No | ~50 | Yes | MIT | Yes |
| OpusMT | University of Helsinki | Link | No | ~230 | No | CC-BY 4.0 | Yes |
| MT5 | Link | No | ~100 | Yes | Apache 2.0 | Yes |
OpusMT emerged as a promising choice.
Made by Helsinki University, it supports translations for over 100 languages in various directions. Each pair of languages has a lightweight model capable of being translated directly and efficiently. Usually, the size of a model is around 100-200MB, which makes it perfect for some low-end machines or Lambda functions.
We verified SageMaker Studio Lab in two configurations:
- T3.xlarge machine with 4vCPU and 16GB RAM, excluding a GPU.
- G4dn.xlarge machine with 4vCPU, 16GB RAM, and 1 NVIDIA T4 GPU.
For comparison, we used a short dataset of three texts in Polish of various lengths and then translated them using Google Translate to learn what to expect from these models.
| Texts | Language | Type | Characters | Words |
| Short | Polish | Weather | 192 | 31 |
| Medium | Polish | Climate | 641 | 82 |
| Long | Polish | Politics | 2430 | 303 |
To show the example this is how short text looked like:
“Jesień to piękna pora roku, kiedy liście drzew zmieniają się w kolorowe odcienie, a wieczory stają się chłodniejsze. To czas, gdy można cieszyć się spacerami w parku i kubkiem gorącej herbaty.”
Translated by Google Translate:
“Autumn is a beautiful time of year when the leaves of the trees change into colorful shades and the evenings become cooler. This is the time to enjoy a walk in the park and a cup of hot tea.”
Translated by OpusMT:
“Autumn is a beautiful time of year when leaves of trees turn into colorful shades and evenings become cooler. It’s a time when you can enjoy walking in the park and a cup of hot tea.”
The difference between those two is negligible. Translation with similar quality was produced by other models as well. Knowing that we needed to consider additional aspects to narrow our choices.
We calculated the performance of all the models running on various machine configurations with CPU or GPU. As you can see, the best performing one was OpusMT, and on GPU it is super fast.
| Model | Processor | Text | Time [s] |
| SeamlessM4T | CPU | Short | 15,7 |
| SeamlessM4T | CPU | Medium | 42,4 |
| SeamlessM4T | CPU | Long | 151,2 |
| OpusMT | CPU | Short | 2,1 |
| OpusMT | CPU | Medium | 3,2 |
| OpusMT | CPU | Long | 5,7 |
| MBart50 | CPU | Short | 18,9 |
| MBart50 | CPU | Medium | 21,5 |
| MBart50 | CPU | Long | 53,4 |
| M2M100 | CPU | Short | 13,1 |
| M2M100 | CPU | Medium | 19,2 |
| M2M100 | CPU | Long | 42,7 |
| SeamlessM4T | GPU | Short | 1 |
| SeamlessM4T | GPU | Medium | 2,3 |
| SeamlessM4T | GPU | Long | 8,3 |
| OpusMT | GPU | Short | 0,2 |
| OpusMT | GPU | Medium | 0,3 |
| OpusMT | GPU | Long | 0,7 |
| MBart50 | GPU | Short | 0,7 |
| MBart50 | GPU | Medium | 0,9 |
| MBart50 | GPU | Long | 2,3 |
| M2M100 | GPU | Short | 0,6 |
| M2M100 | GPU | Medium | 0,9 |
| M2M100 | GPU | Long | 2,1 |
Considering all the aspects of such models, such as licensing, model weight, ease of use, performance, and quality, we have finally opted for OpusMT.
Implemented solution
We’ve opted for the EasyNmt Python library to handle the heavy lifting for us. This library conveniently provides a pre-built container with a functional API, making it a breeze to set up on EC2. Check out the setup guide here.
We’re mindful of the EC2 costs – juggling infrastructure maintenance, manual updates, and setting up auto-scaling can be a handful. So, we’ve put that on hold for the time being. Real-time translations aren’t our immediate need; most of the time, EC2 won’t be in the spotlight.
Our game plan? Give AWS Lambda a shot to trim down those costs.
AWS Lambda
Understanding the limitations of AWS Lambda, especially regarding storage capacity, is crucial. This necessity underscores the rationale for utilizing containerized Lambdas.
In this context, the code package size within a container Lambda can reach up to 10GB, and with the additional ephemeral storage available in “/tmp” (up to 10GB), the total capacity is 20 GB. This enables the creation of customized containers housing 6-7 pre-downloaded models, each approximately 300MB. This approach eliminates downloading these models on demand when the Lambda function initiates.
When models haven’t been pre-downloaded, the initial translation time for text containing around 4,000 characters is approximately 15 seconds. During Lambda initialization, tasks include accelerating the Virtual Machine, loading the container, analyzing the text’s language, downloading the required model, and loading it.
Once these steps are completed, subsequent requests will take approximately 5 seconds for the Lambda function to provide answers.
The EasyNMT library includes a remarkable utility that can automatically recognize the language of a given text. Additionally, it dynamically downloads the necessary model on the fly, streamlining the process and improving efficiency.
Developing the machine translation solution
In our client projects, we have typically utilized the Serverless Framework. However, I have employed the SST Framework to construct our serverless solution for this case.
The SST Framework offers a modern and developer-friendly experience for building serverless applications on AWS. It simplifies defining and deploying serverless infrastructure using TypeScript, making our code type safe.
Under the hood, SST constructs leverage AWS CDK, giving developers access to raw CDK functionalities if needed.
To kickstart our project, let’s begin by initializing with the following command:
`npx create-sst@latest serverless-translations`
Building containers in Dockerfile
This Dockerfile is designed to establish an environment for executing our translation Lambda function, utilizing the Opus-MT model and essential dependencies and code.
Let’s delve into the purpose of each section:
1. `FROM amazon/aws-lambda-python:3.9`
Specifies the base image for the Docker container, utilizing the amazon/aws-lambda-python image tailored for running Python Lambda functions with Python 3.9.
2. `COPY ./requirements.txt /requirements.txt`
Copies the local requirements.txt file into the container’s root directory.
3. `RUN yum -y install gcc-c++`
Installs the gcc-c++ package via yum, which is likely necessary for building specific Python packages involving C or C++ code compilation.
4. `RUN pip install –no-cache-dir torch –extra-index-url https://download.pytorch.org/whl/cpu`
Installs the PyTorch library without caching files, specifying the extra index URL for downloading PyTorch. Additionally, it indicates the use of the CPU version since it’s intended for Lambda.
5. `RUN pip install –no-cache-dir -r /requirements.txt`
Installs Python dependencies listed in requirements.txt using pip. The –no-cache-dir flag ensures that no cached files are utilized during installation.
Our requirements.txt:
6. `ENV HOME /tmp`
This directive establishes the HOME environment variable within the container, setting it to /tmp. This step is crucial because EasyNMT may attempt to download files or models, and without this line, it might try to store them outside of Lambda’s ephemeral storage, leading to errors.
7. `COPY handler.py ${LAMBDA_TASK_ROOT}`
This command copies the local handler.py file into the Lambda task root directory within the container. This ensures that the Lambda function can access and execute the specified handler.
8. `CMD [“handler.main”]`
This instruction defines the command to execute when the Docker container starts. It specifies running the primary function from the handler.py file. Essentially, this sets the entry point for the container’s execution, indicating the starting point for the Lambda function within the container.
Lambda handler
Now, let’s implement our Lambda logic.
The code execution unfolds as follows:
- Input Retrieval
Begin by obtaining the target language code from the path parameters. Then, extract the source text from the request body, which is intended for translation.
- Parameter Validation
Conduct basic validation checks on the provided parameters.
- EasyNMT Integration
This code section utilizes EasyNMT to load the “opus-mt” model and automatically detect the source text’s language. The primary action involves invoking the ‘.translate’ method and awaiting the result.
- EasyNMT Workflow Details
Internally, EasyNMT checks if the source_language is provided as an argument; otherwise, it automatically attempts language detection. Based on the target language provided, EasyNMT seeks and downloads the desired translation model. The acquired model is then utilized to translate the source text.
- Project Structure
The Dockerfile, handler.py, and requirements.txt files must be placed in the packages/functions/src/translation directory.
- SST Configuration
To consolidate the different components and establish connections, create a new file under the ‘stacks’ directory and name it, for example, ‘Translations.ts’. This file acts as the central piece connecting the various elements using SST (Serverless Stack Toolkit).
This function serves multiple purposes. During deployment, SST will search for a Dockerfile in the specified path in the ‘handler’ argument. It will then build a container and push it to the AWS Elastic Container Registry, facilitating the connection between the containerized function and AWS Lambda. As a result, the function returns to obtain its reference in other stacks.
With the Lambda function established, I’ll show you how to create a simple API easily using SST.
Create `Api.ts` under the ‘stacks’ folder.
In the initial steps, refer to the translation function created earlier using the SST hook. Subsequently, SST’s API construct will be employed, facilitating the creation of API Gateway resources and the connection of Lambdas to them.
The API construct offers robust functionality, incorporating authentication, proxy routes, GraphQL integration, and more features. However, for the sake of simplicity in this example, we are keeping our configuration straightforward.
It’s important to note that the SST construct acts as an abstraction layer on top of the AWS Cloud Development Kit (CDK). This abstraction enables us to access CDK properties within SST. Our example demonstrates this by linking the translation function to a specified route.
The final step involves connecting our stacks in the `sst.config.ts file`. This step likely involves configuring the dependencies and relationships between the different components or resources created in the SST application.
Now let’s have fun with SST and utilize its power. We will extend the example above to create an army to translate Lambdas with pre-downloaded models. It could be handy if you want to avoid being charged for download transfer to a Lambda or if your Lambda is in a private subnet and, therefore, without access to the internet.
Let’s create a similar lambda, but now in a more generic way:
We’re utilizing docker multi-stage builds. We download the desired model in the first step and copy it to our final build.
Next, we have to adjust our handler a little bit:
Now, let’s revisit our Translations stack and create a function that will dynamically generate lambda for us.
Now all you have to do to create an army of lambdas is to extend our ‘LANGUAGE_PAIRS’
Our code will iterate over those pairs, and as long as there is an Opus-mt model, then lambda will be created.
All that’s left is to import those functions in our API stack, map them, and spread them in an API construct.
…and now everything is ready to deploy.
`npx sst deploy`
Cost? Down from $200 to $1.95 to generate one report with 4k articles
Previously, we highlighted that using dedicated services to analyze 4,000 articles containing 4,000 characters would exceed $200.
Now, let’s break down the pricing calculations for our solution:
Total Compute Charges:
- 4,000 requests x 5,000 ms x 0.001 ms to sec conversion factor = 20,000.00 total compute (seconds)
- 5.859375 GB x 20,000.00 seconds = 117,187.50 total compute (GB-s)
- 117,187.50 GB-s x 0.0000166667 USD = 1.95 USD (monthly compute charges)
Total Request Charges:
- 4,000 requests x 0.0000002 USD = 0.00 USD (monthly request charges)
Ephemeral Storage Charges:
- 1 GB – 0.5 GB (no additional charge) = 0.50 GB billable ephemeral storage per function
- 0.50 GB x 20,000.00 seconds = 10,000.00 total storage (GB-s)
- 10,000.00 GB-s x 0.0000000358 USD = 0.0004 USD (monthly ephemeral storage charges)
Total Lambda Costs (Without Free Tier) = Monthly Compute Charges + Monthly Request Charges + Monthly Ephemeral Storage Charges:
- 1.95 USD + 0.00 USD + 0.0004 USD = 1.95 USD
Comparing this to the dedicated translation service cost of $200, we observe a remarkable cost reduction of 99%, down to only $1.95! Therefore, our Lambda-based solution is significantly more economical, providing substantial savings for the business.
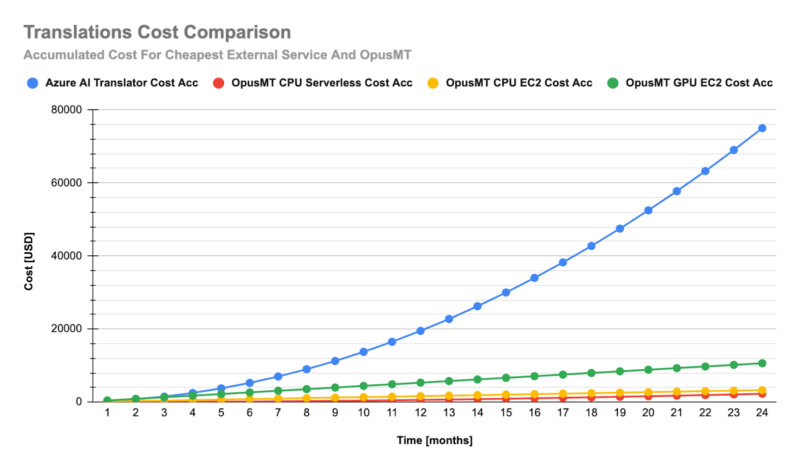
Regarding solutions based on various implementations of OpusMT (serverless vs. CPU vs. GPU), the cost is reduced significantly, down to around $2200!
This can be reduced even further thanks to EC2 Reserved instances. Eventually, the lowest cost we could achieve was around $1000. When we compare it to the most expensive external service DeepL which would cost around $150000, the reduction is over 99%.
Benefits of machine translation software
The most prominent business benefit of this project was enormous money savings!
OpusMT can reduce translation costs (including infrastructure) by over 99% and is still very performant and accurate.
Thanks to Serverless, we did not need any DevOps support and could implement it in no time. Serverless eliminates the need to manage servers, as the cloud provider automatically handles scaling, maintenance, and other operational tasks.
Serverless architecture often saves a lot of time. The process ensures efficient and faster development because developers can solely focus on writing code without dealing with server provisioning and management.
Machine translation development. Lessons learned
Hugging Face
One of the best discoveries is the abundance of lightweight models on Hugging Face, each designed for specific tasks. This approach allows for the quick adaptation of R&D to meet project requirements and select a customized solution. To illustrate, in a recent case for a different client, we identified a distinct model on Hugging Face within just two days of research, addressing a completely different task related to text classification.
LLM is not a one-size-fits-all solution
While Large Language Models may appear powerful, they are not a universal solution for every problem. Their limitations include slower processing speeds, higher costs, and issues inherent to LLMs, such as hallucinations. Dedicated models designed for specific tasks often outperform LLM drawbacks in these respective areas.
Popular doesn’t mean effective
We’ve discovered that particular custom solutions can surpass the capabilities of industry giants like AWS, Azure, or IBM. It’s possible to obtain more cost-effective and equally or even more accurate translations than those provided by services such as Google Translate. However, many individuals and companies may overlook this option and immediately opt for the services of well-known brands, potentially risking unnecessary expenses in the long run. The choice ultimately depends on each user or organization’s needs and priorities.
R&D is NOT a waste of time and money
Investing in research and development is valuable to identify a suitable model tailored to the unique needs of your project. Every factor needs to be considered – company size, industry, reach, target user groups, security, law compliance, long-term business goals, team expertise and skills, budget, time constraints, etc. Potentially, it can lead to new business opportunities.
AI can boost productivity, cut costs, and drive business growth for you too
AI only works when it’s aligned with your goals and technologies. Book an hour long, free consultation with our AI team to see if/how you will benefit from introducing AI.
