04 April 2024
AI for publishers. Comparing AI name extraction software for more user engagement



Contents:
A company from a publishing business aimed to use AI to analyze its content and boost inclusivity, especially for underrepresented women in their industry. By focusing on extracting names and genders from text, the project provided data-driven insights to drive engagement among diverse audiences. Rigorous testing of AI solutions, including Google Vertex AI, GPT-3.5 Turbo, and spaCy, helped identify the most accurate and cost-effective toolset, highlighting AI’s potential in content analysis.
Project background. AI for the publishing industry
This project was conducted for media publishers (NDA).
The client’s mission was to welcome and cater to women not so widely represented in their existing content. The magazine needed an analysis tool to identify popular content among women and compare the results with analytical data.
The critical challenge in this text analysis was to discern whether the text predominantly focused on women or men. To address this need, we sought a ready-to-use tool that could effectively extract individuals from the text and accurately determine their gender. Eventually, the results will serve as data-driven business insights for informed decisions, driving sales among women (and later, other target groups).
Business requirements
Our partner’s goal was to identify people in the text and recognize their gender accurately to achieve automated big data for future decisions regarding their growth.
The project aimed to create a sophisticated AI analytics tool for publishers, drawing a diverse audience and uncovering growth methods. Using advanced algorithms and machine learning, it analyzes content for biases, enabling the creation of inclusive material. The platform provides actionable insights on audience interactions with content, suggesting ways to improve reach and engagement.

Artificial Intelligence & Natural Language Processing
Given the nature of the task, we opted for a tool utilizing Artificial intelligence (AI), specifically NLP (Natural Language Processing).
NLP is a branch of artificial intelligence focusing on the interaction between computers and human language. Developing algorithms and models that enable machines to understand, interpret, and generate human-like text.
NLP technology is crucial for:
- language translation,
- sentiment analysis,
- text summarization,
- speech recognition.
In the context of our task, employing NLP means harnessing advanced techniques to enhance human speech analysis. Such capabilities make deciphering and extracting meaningful insights from human language significantly easier.
Large Language Model (LLM)
LLM is a computer program designed to comprehend and produce human language effectively. This advanced form of artificial intelligence has undergone comprehensive training to enhance its ability to understand and generate text.
LLMs are versatile tools for:
- text composition,
- question answering,
- language translation.
Names extraction. Analyzing available tools (so you don’t have to)
The first step is always thorough market analysis – this time, we’re looking for tools that locate people’s names in written text and figure out the gender of those people mentioned.
We divided our analysis into two parts:
- Extracting individuals from the text.
- Recognizing gender based on first and last names.
For testing, we picked various articles, some in English and some in other languages, to see how well these tools find names in actual publications.
Compromise
![]()
Compromise is an NLP JavaScript library available on GitHub, designed to facilitate easy and efficient text processing in understanding natural language. It provides a range of powerful features, including tokenization, stemming, part-of-speech tagging, and named entity recognition.
With its user-friendly syntax and comprehensive functionality, Compromise is a valuable tool for developers seeking to analyze and manipulate textual data in JavaScript applications, making it particularly useful for tasks such as language parsing, sentiment analysis, and information extraction.
Compromise was our first choice because it’s free, you can run it in the Node runtime, and the implementation is simple and fast. In the first version, we used it as a tool for name extraction and gender recognition.
Let’s start with an example:
And the result is:
Sometimes, Compromise returned two individuals in a single object separated by a comma or duplicated individuals (for example, Lisa and Lisa). How to handle these duplicates?
After removing those duplicates, the response looks fine, but it cuts some results (if only firstName or secondName is mentioned).
As you will see in subsequent studies, compromise struggled with a larger number of individuals and often failed to recognize all people correctly. We decided to try different providers.
Google Vertex AI
![]()
To test well-known AIs, we needed to look into Google Vertex AI. We used the gemini-1.0-pro-001 language model.
Google Vertex AI streamlines the E2E machine learning workflow, providing tools and services for data preparation, model training, and deployment tasks. It includes pre-built models, automated machine-learning capabilities, and tools for collaboration, making it a versatile solution.
However, despite having other GCP products in the project, the client could not use Google Vertex for legal reasons.
GPT-3.5 Turbo (OpenAI)
![]()
GPT-3.5 Turbo models understand and generate natural language or code. I couldn’t help but wonder about its accuracy, so I tested this popular and relatively easy tool.
The most important thing is to write the correct prompt, and mine went like this:
And the response:
GPT-4 (OpenAI)
![]()
The main difference between the GPT-3.5 Turbo and GPT-4 is the number of parameters (components containing the information acquired by the model through its training data):
- GPT-3.5 has 175 billion parameters,
- GPT-4 has approx.1 trillion parameters.
An API call with the given body:
One call depends on the article’s length. It was between 500 and 1500 tokens:
- GPT-3.5 Turbo costs $0,0090 per 1k tokens,
- GTP-4 costs $0,09 per 1k tokens.
The pricing is up to date as of February 2024 and is changing rapidly. The latest pricing can be found here: https://openai.com/pricing
So GPT-4 is 10 times more expensive! If you don’t prioritize higher accuracy with GPT-4, it’s better to use GPT-3.5-turbo. The difference in cost is not proportional to the accuracy.
spaCy JS
![]()
SpaCy is a NLP library and toolkit for Python. It provides pre-trained models and efficient tools for tasks such as tokenization, part-of-speech tagging, named entity recognition, and more.
Few libs allow running spaCy in a Node environment, e.g., spacy-js. To speed it up, we ran it in Python with Nvidia GPU. As an HTTP server, we used Flask.
Using the documentation example below, we tested the most popular spaCy models.
After a few tests, we decided to try SpanMarker. It allows the use of pre-trained SpanMarker and training your model.
Example span marker implementation:
Now, the most exciting part, you can connect these two models using spaCy in the following way:
This code uses the SpaCy library and a pre-trained transformer-based English language model (en_core_web_trf). Additionally, it adds a custom pipeline component, span_marker, which is loaded from the model with the name lxyuan/span-marker-bert-base-multilingual-cased-multinerd.
This is only a fraction of the solutions available on the market. So, let’s start testing them on authentic articles.
Tests in practice
Articles we used
For comparison, we took a variety of online articles (it’s a different batch than the original one, we use different examples to illustrate the technical process):
- standard English with a large number of people mentioned (The Independent),
- English from Middle Eastern medium with African names and surnames (AlJazeera),
- Polish ultimate test with a football league article (Dziennik Zachodni),
- Croatian ultimate test with a football league article (Jutarnjeg).
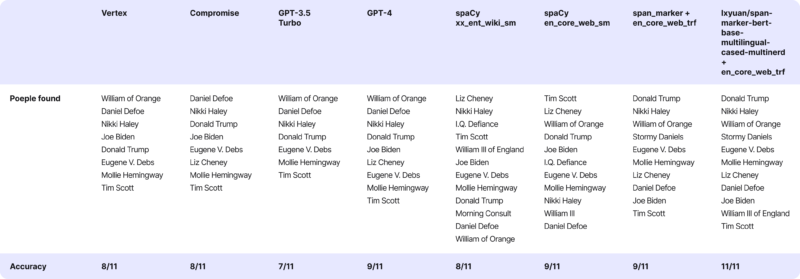
Additionally, we conducted a similar thing with this article from The New York Times.
Firstly, we read the article and manually found the names. Then, we used tools to do the same thing for me. You can check out the results below:
People mentioned in the text:
- William of Orange
- Daniel Defoe
- Nikki Haley
- Joe Biden
- Donald Trump
- Eugene V. Debs
- Stormy Daniels
- Mollie Hemingway
- Tim Scott
- Liz Cheney
- William III of England
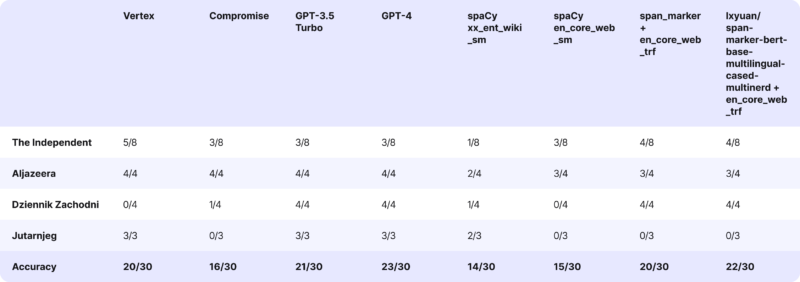
Now, let’s see how the tools performed. For the correctly recognized person, we add +1 point; for missing a person, we deduct -1.
Conclusions
- Google Vertex performed very well with both English and Croatian articles. Still, the Polish article treated football clubs as people’s names.
- Compromise found approximately two-thirds of individuals in the article, even in the case of accessible articles. For the more challenging ones, it performed even worse.
- GPT-3.5 performed nearly flawlessly, recognizing individuals in Polish and Croatian articles.
- What GPT-3.5 couldn’t accomplish, GPT-4 did. We could conclude the tests at this point, focusing on optimizing the prompt for GPT-4. However, we couldn’t use this solution for legal reasons.
- Regarding spaCy models, the most popular ones performed moderately well with English articles but poorly with non-English ones. Both multilingual models marked with ‘xx’ and English models marked with ‘en’ could return the same person twice. Filtering out duplicates proved quite challenging.
Tests results. Span Marker – the win in the names extraction category
The first place goes to lxyuan/span-marker-bert-base-multilingual-cased-multinerd + en_core_web_trf.
The client decided based on their tight business and legal requirements (e.g., keeping everything on their tailored-made machine).
The most accurate among the models we tested and could use following client’s wishes was lxyuan/span-marker-bert-base-multilingual-cased-multinerd, combined with the spaCy model en_core_web_trf. We know it’s a mouthful. Additionally, we fine-tuned it through tokenization and other peculiar adjustments. This tool handled English articles well but needed some help with Polish and Croatian.
However, if you find yourself facing a similar choice, OpenAI is the best option at the moment.
Gender detection. Available solutions.
When selecting a tool for gender detection based on names, our initial exploration focused on the most popular tools available. We considered:
- Gender API,
- Genderize.io,
- NamSor,
- Wiki-Gendersort.
Many of these tools had their performance evaluated in studies and comparisons to facilitate our decision-making process:
- Paul Sebo (University of Geneva) – How accurate are gender detection tools in predicting the gender of Chinese names?
- Group work (University of Toronto) – Gender inference: Can ChatGPT outperform common commercial tools?
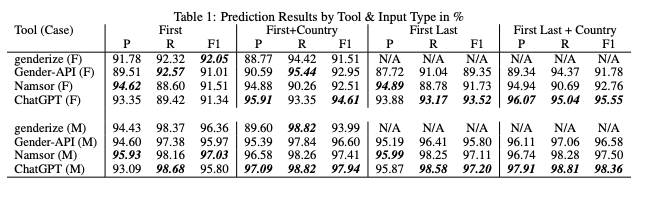
Source: Gender inference
In this context, opting for a gender recognition tool based on names was relatively straightforward.
After careful consideration, we chose Genderize due to its affordability and reasonable accuracy. Genderize is nearly ten times cheaper than other tools, with only slightly less accuracy! The price-to-accuracy ratio was the most critical factor for our needs (used as a backup in MVP).
Notably, the availability of a free demo account played a crucial role in the initial stages of our application. The demo account proved sufficient to handle the traffic and served as a cost-effective solution for our needs.
Additionally, we considered NameSor’s client, acknowledging its high accuracy. However, as we delved deeper into our implementation, it became apparent that Namesor was a far more expensive option.
We reevaluated the strategy and made adjustments to our toolset. After a few weeks, our approach evolved into a more sophisticated one. We began by querying Google Knowledge Graph and then Wikipedia. If an article about a specific person was located, we analyzed the pronouns to determine gender. In cases where no relevant article was found, we seamlessly utilized Genderize as a reliable backup solution. This combination of tools allowed us to enhance the accuracy of our gender recognition process while maintaining cost-effectiveness and efficiency.
Gender detection tools cost comparison
Let’s assume (100 000 articles * 5 names) / month
In the case of OpenAI, we will apply optimization by querying all five names in a single API request.
| Name | 1 request | 500k requests |
| Genderize | $0,00012 | $60 |
| NameSor | $0,0013 | $650 |
| GPT-4-0613 | $0,00513 | $513 (100k requests!) |
| Gender-API | $0,0008 | $399,95 |
Implemented solutions
Finally, we chose Span Marker (hosted on ec2 with Nvidia graphics) only after a few tweaks in the final code.
In the code snipped above, function extract_people:
- takes a text and a model as input,
- tokenizes the text into sentences and words using NLTK,
- creates a data dictionary with token information,
- creates a Dataset from the data dictionary,
- makes predictions on the dataset,
- filters entities to include only those labeled as ‘PER’ (persons),
- formats and returns the names of the extracted people.
Through testing, it turned out that sentence tokenization is beneficial.
Machine scaling and cost comparison
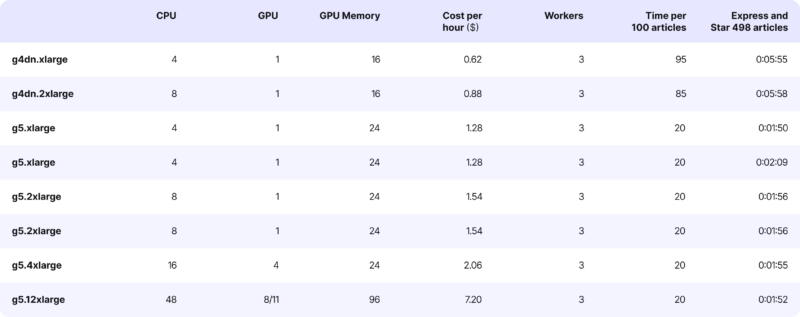
After the tests, we decided to choose g5.xlarge with autoscaling enabled.
The g5.xlarge belongs to the G5 series of instances in AWS EC2, explicitly designed for tasks requiring significant graphics processing power. They’re ideal for machine learning, high-performance computing (HPC), and graphics rendering applications.
The biggest issue with GPU instances is their cost
In our case, the g5.xlarge costs one dollar per hour, which amounts to over 700 dollars a month, not including scaling.
Now, let’s discuss scalability. We leveraged the built-in auto-scaling feature in EC2, which was based on CPU load metrics. In the event of increased traffic, we automatically launched additional machines. AWS seamlessly directed the traffic to these machines based on the CPU load metric.
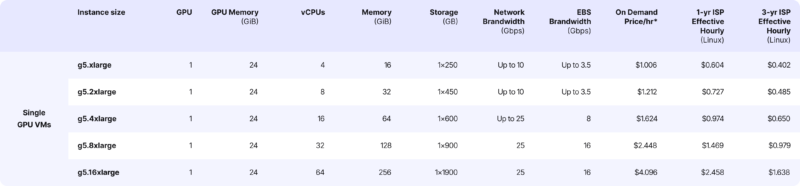
Let’s assume 100,000 articles/month, where one article equals 2000 characters. For Vertex and GPT it means 2000 tokens.
| Name | 1 request | 100k requests |
| Vertex | $0,001 | $100 |
| Compromise | free …but you need to pay for the infrastructure | free …but you need to pay for the infrastructure |
| GPT-3.5 | $0,0018 | $1800 |
| GPT-4 | $0,18 | $18000 |
| spaCy | $0,012 | $1200 |
Project benefits
In the case of this project, we aimed to identify people in the text and recognize their gender accurately. Automation accuracy and keeping everything on a custom machine were crucial.
Hence, the choice fell on spaCy + SpanMarker.
By changing Compromise to a Python model, we could boost accuracy. Our tests showed that Compromise identified half of the individuals, while Spanmarker found significantly more instances.

Lessons learned
Although this project was conducted and customized for a specific client, we gathered insights valuable for anyone looking to implement name extraction:
- OpenAI has the most accurate tools. However, big international businesses require strict data security and extra requirements related to local regulations. So, there are cases where you mustn’t use OpenAI.
- Many companies fear using OpenAI for their data security and prefer to host something of their own, e.g., LLaMA or Mistral.
- An OpenAI version is hosted in high isolation on Azure (OpenAI for Azure). This solution is often used by companies in the healthcare industry precisely because of increased security.
- In this case study and other projects we have conducted, we see that GPT-4 is much more accurate than GPT-3.5.
- GPT-4 is the most accurate tool but simultaneously the most expensive. So, if money is not an issue and accuracy is the number one priority – go for it.
- Vertex is precise enough for its affordable pricing.
- Sometimes, it is worth setting up your own infrastructure and using a ready-made model for analysis rather than using LLM. A highly specialized pre-trained model is better than a generic LLM
- The time-to-market using GPT is much lower than when using ready-made models (due to infrastructure, configuration, etc). You just run GPT, and it works.
- Setting up your own infrastructure comes with challenges (managing, updating, maintaining, etc.). While it is profitable on a larger scale, it may not be cost-effective on smaller-scale projects.
We elevate your projects with data-based AI expertise!
From cutting-edge solutions to personalized support, unlock the full potential of AI-driven innovation for your business needs. Book a free consultation with our experts by clicking below.
