09 March 2023
Tech study: Data migration plan with AWS cloud services for GOconnectIT




Contents:
A good data migration plan is a must, especially when moving data between two complex systems (a legacy system and a new one) that are both continuously operating. Migrating data, when you transfer data worth terabytes or work with sensitive data, is extremely demanding. So, in order to ensure data quality for GOconnectIT, our data migration specialists created a custom, AWS cloud-based solution that supported and future-proofed GCI’s business processes.
Why did GOconnectIT look for a technological partner?
GOconnectIT is a company from the Netherlands creating professional software for managing the installation of optical fibers for private homes and businesses.
It’s one of the leading companies in the utilities industry, working with 50+ customers, contractors, and network operators. They specialize in providing GEO information, supporting innovations at infrastructural projects, reducing damage to cables and pipelines, and making sure that all necessary deadlines and procedures are met.
The company had two products for Fiber rollout (FTTH), one of which was designated as end-of-life, intending to move all customers to the newer product – GO FiberConnect.
The initial analysis showed that:
- the old, legacy system has a very rigid logic,
- the data is extensive and complicated.
The main problem we had to solve together was the configuration which differed depending on GOconnectIT’s customers and their end-users. Often multiple customers work for the same client and then the configurations should be identical. Unfortunately in FiberConnect, it varied and more data engineering work was necessary.
The data migration plan was just one part of a much larger project for GOconnectIT
Check out the full scale of our cooperation in the business case study below 👇
Initial problems and a lesson learned
Every project brings a lesson, sometimes a harsh one. From this experience, we gained an even stronger conviction that ETL projects require a huge commitment from both parties, domain experts, and a separate and meticulous analysis phase. Without a fixed plan, the implementation time will be subject to constant change. Due to the complexity of the project needs and very strong alignment with the client, our assumptions have evolved over time which had a direct impact on how we finally conducted the project. We became convinced that it was worth spending more time on the analysis phase.
At first, it seemed that the task would consist of transforming the data from the relational database and entering it into the appropriate target system database. Data migration wasn’t only at the relational database level, but also required integration with the new system through its API.
For these reasons, using existing solutions for database migration operating at the SQL level was out of the question.
So, how did our data engineering services solve this?
Data migration strategy. AWS cloud – we choose you!
For the database migration, we picked AWS cloud, and more specifically the following services:
- Lambda,
- Step Functions,
- SQS,
- Parameter Store,
- DynamoDB,
- S3.
We chose this stack because we already have vast experience with rate limiting on Lambdas. We needed a solution to determine how fast the data is processed to the new system, and how fast is data downloaded from the old system.
Additionally, we required a service that would allow us to save the current state of the migration (errors, which data was migrated and which wasn’t, etc.), so if necessary, we are able to process only non-migrated data without having to delete the old ones and migrate again. In this case, we decided on DynamoDB as a fully serverless, non-relational database designed to process huge amounts of data (ETL).
Reusing TCP/IP connections on Lambdas? Why not!
One of the reasons some people may frown upon building a complex migration strategy that fetches/uploads data from/to a relational database using Lambda functions is reusing TCP/IP connections.
Lambda is a classic FaaS (Function as a Service), i.e. a software development model based on code execution on virtual machines fully managed by a cloud provider. As FaaS users, we only need to provide the function logic (exported as a handler), which will then be imported by the virtual machine and eventually run.
It may seem like you have to re-establish the TCP/IP connection to the database every time you execute a Lambda function. As you know, establishing such a connection is time-consuming and the number of parallel connections is usually limited.
However, there are two ways to reuse the same TCP/IP connections to the database:
- Using Amazon RDS Proxy
This way is only possible unless you use Amazon RDS or AWS Aurora as your database service. Amazon RDS Proxy allows your serverless applications to share connections established with the database. Once the connection is settled, RDS Proxy takes care of it and when another Lambda wants to connect to the database, it doesn’t need to create a brand new connection, but it will be served with an already existing one.
- Moving the TCP/IP connection out of the Lambda handler
Another way, which is applicable no matter which database service you use (on-premise/cloud/etc.), is about reusing the same connection across a single Virtual Machine where the Lambda functions are running.
The secret is to take the initialization of the connection outside of the exported handler function. Thanks to this, the connection will be established only once and will last as long as the virtual machine is alive (usually around 15 minutes).
More optimizations like this are described by AWS themselves. In The Software House, we use them very intensively, so we highly recommend the read.
Data migration process under the microscope
Long story short: we built an ETL mechanism that retrieves information from the source database and puts it on the queue. Then the ETL processes the queued data and enters it into the target system.
Now, onto the details.
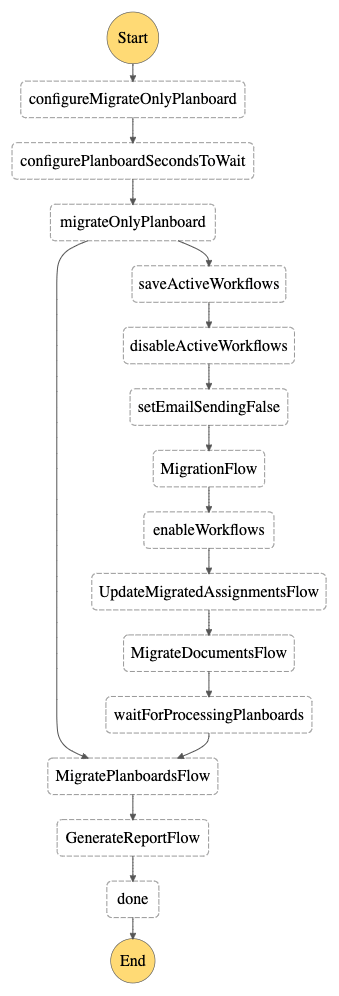
So, what’s with the graph? Let’s analyze it step by step in order to understand what’s going on under the hood:
1. The process starts with the steps configureMigrateCompletedProjects and configurePlanboardSecondsToWait.
These are some simple ones that configure the parameters which are used later in the entire flow. The user can either manually provide the values when starting the migration or – if they are omitted – they will be populated with some default values.
2. Step migrateOnlyPlanboard is a classic AWS Step Functions Choice state.
Call it a simple if statement. Based on the input parameter that the user specified (or that was populated automatically with a default value), the flow can split into two paths – it can either skip most of the flow and go right to the MigratePlanboardsFlow, or go gracefully step by step. The migrated system is pretty complex, that’s why data migrations also have to be configurable in order to address various use cases. Step MigratePlanboardsFlow depends on the new system’s asynchronous jobs completion status. Sometimes we know what is the status of these jobs and we can go straight to this step. Sometimes we don’t – and we have to traverse the flow’s full path.
3. Steps saveActiveWorkflows, disableActiveWorkflows, and setEmailSendingFalse.
They are there to configure the status of the new system before the data transfer. They are like the warmup before the game – some minor tweaks and tricks before actually moving data.
4. Steps MigrateFlow, UpdateMigratedAssignmentsFlow, MigrateDocumentsFlow are the ones where the real data migration happens!
They are categorized by the entity name that is currently being migrated. However, one of them called MigrateFlow migrates a few of the resources that are logically connected with each other. That’s why they were placed together under a common step. Also, all of them are separate AWS Step Functions! Why? Not only that helps to group common parts of the process under nicely named, separate AWS Step Functions and track the migration process very precisely from the business perspective, but also helps to overcome the limitations of history events per step functions.
During AWS re:Invent 2022, a distributed map was added as a flow which is excellent for orchestrating large-scale parallel workloads. Every iteration of the map state is a child execution with its own event history – which means you won’t run into a 25,000 history events limit per parent’s Step Function execution.
5. The next step – waitForProcessingPlanboard – is an AWS Step Functions Wait state.
Remember when we told you about these asynchronous jobs in the new system that have to be executed before going forward with the migration? If we know that these jobs haven’t been finalized yet, we have to wait a bit. Here goes the… wait step. Badum-tss!
6. MigratePlanboardFlow is another stage where data migration happens.
This is this nasty step that’s dependent on these asynchronous jobs execution. Since we know that at this migration stage, all of them should be already executed, we can proceed forward.
7. Last but not least, GenerateReportFlow step is triggered.
It generates a set of reports which contain a summary of the migration process:
- how much data was successfully transferred from the old to the new system,
- how much data was not migrated,
- why the remaining data could not be migrated
- the duration of the migration process, etc.
Running operations per sub-project
Since we had to migrate not one, but many databases, we couldn’t simply run one Lambda Function and command it to perform the migration process for all of the databases. That’s because of some hard Lambda-level limitations like maximum execution time.
Because of that, we had to think of some general solution that could go through all of the databases and run the migration process for them. The diagram below illustrates our approach (which is – you guessed it – another AWS Step Function).
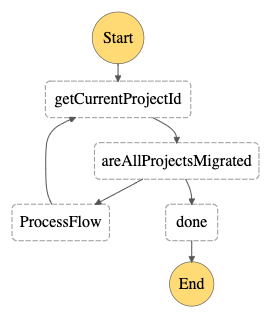
ProcessFlow is run using a dynamic variable holding the ARN from the Step Function that will be called. This not only allows us to group the process logically – by sub-projects – but also to reduce the number of historical events in a single Step Function (the limit mentioned earlier in the article).
Resource migration process
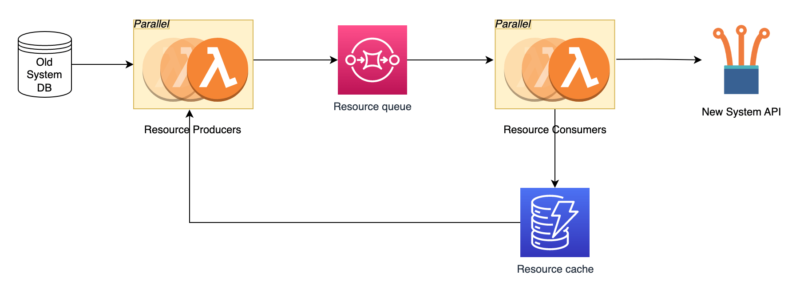
The diagram above presents a generic resource migration process that starts with downloading data in batches from the old system’s database.
Producers are the only part of the process that interacts with the legacy system’s database to fetch data for migration. Thanks to the fact that the data is downloaded in pieces – instead of one at a time – and thanks to the concurrent downloading of data using several lambda functions, the time for which the database is loaded has been significantly reduced.
Then Producers check in DynamoDB (resource cache in the graph) whether the downloaded data has been migrated. If the entity hasn’t yet been migrated, the Producer generates a message that contains all the necessary information needed to migrate it. Thanks to this solution, further steps of the migration process no longer need to communicate with the database of the old system again. That makes the process much more flexible, loosely coupled, and error-proof.
Going further, consumers retrieve messages from the queuing system, map the data to a format acceptable by the new system and send data using the API (or if there is no appropriate endpoint – directly to the database but this time the database of the new system). The result of single resource migration is saved in DynamoDB (the same DynamoDB where Producers previously verified whether a given resource had already been migrated or not).
Modeling the process and using DynamoDB as a cache makes the operation of the migration system idempotent – what has already been transferred will not be transferred again. In addition, DynamoDB performs an audit function here. If the resource failed to migrate (e.g. because its data was not accepted by the new system) an appropriate error message and the entire payload that was used will be saved in the database.
On 12th January 2023, AWS added support for setting the Maximum Concurrency of Amazon SQS out of the box, hence the trick described here is no longer needed.
The key element of the migration process was the use of an AWS FIFO-type SQS queue that allows you to maintain the order of processed messages. This queue has a rather interesting feature to control the concurrency of our Lambda Functions.
In ETL processes, controlling the processing speed is crucial. This is extremely important when entering into communication with services such as a database or API – in order not to kill these services with too many requests, we need to control the number of requests per unit of time with clockwork precision.
The FIFO queue allows you to assign the MessageGroupId attribute to messages, specifying to which group a given message belongs. Due to the fact that the order of message processing on this type of queue must be preserved, the number of unique MessageGroupId attribute values determines how many instances of the Lambda function can process messages at a given moment.
By properly classifying messages into different groups, we control the speed and concurrency of data processing, thus adapting to the limits of the system we are currently migrating.
What’s specific about GCI database migration? Project benefits
The legacy system is no longer supported and will be discontinued. The migrated data will allow continued roll-out and management of the installed optical cable infrastructure.
The migration is error-proof. Records that failed to be processed end up in a separate place where they can be reanalyzed and reprocessed.
We are able to regulate the speed of both data downloading from the source database and uploading them to the API of the new system. This helped us schedule maintenance for times when it is least disruptive to users. It’s always important to exactly analyze the amount of data, otherwise even the most thorough performance tests won’t help the performance issues.
The solution is fully automated. Once planned migration (migrating selected clients) will be performed entirely automatically. Considering the scale of the migration (millions of records/TB of data), there’s no need for a person to constantly manually check it.
After the migration is completed, the system generates a set of reports that contain a summary of the migration process (post-migration audit if you will). Due to the fact that the old system contains a lot of inconsistencies in the data, this report is a significant help – it shows exactly at the testing stage which data is faulty and what end users need to fix before the production migration.
GOconnectIT’s data migration project. Summary
With a solid data migration strategy, we’ve successfully transferred terabytes of data from a legacy system where it was stored in a relational database, and transformed it to a format digestible by the new system.
We’ve completed the data migration plan in a fully controlled manner, iteratively refining the logic behind the data transformation, as well as the data quality of the records that could not be migrated.
“TSH has been able to help us in times of trouble”
– quote from Bart van Muijen (CTO, GOconnectIT). If you struggle to control your company’s data, we’ve got a dedicated migration team who will solve your data migration problems too. We offer free, 1 hour consultations for anyone wanting to talk about their software solutions and how to improve them. No strings attached, so why not try?
