29 April 2021
Sports activities and serverless – the architecture for data-driven systems


A few years ago at The Software House a new initiative was launched – TSH Challenge. The idea was simple, let’s count the kilometers we run/walk/ride and convert those into points, so we can motivate each other to a healthier lifestyle. The idea was a great success and soon it evolved into a lottery where each point gave you a lottery ticket, allowing you to win something. We could end it here, but this was just a beginning. Let’s talk about sports activities and serverless and how we build an architecture for data-driven systems.
Endomondo
The first version of the app didn’t come with any special requirements or features. We only wanted to calculate the points and track user activities. In fact, it required little coding from us, because most of the functionalities were handled by Endomondo.
It had a feature called challenges that we could use to gather necessary information from all the users from our group.
We had to build a parser, which was done with a simple PHP script, executed every few days on a DigitalOcean droplet. Yeah, it doesn’t sound exciting at all. It was really simple! Of course, the initial design had some flaws, we soon discovered…
The end of Endomondo
At the end of 2020, Endomondo announced they were shutting down the platform. Every user had time until December 31 to transfer activities into a different system. It was fine for a standard user, yet much more complex for systems that depended on Endomondo special features, like those challenges we were using. 😅
So since we didn’t have a choice, but to change a provider, we decided that maybe it is also a good moment to rethink the whole application and finally remove all the flaws we found.
We started making our decisions regarding the architecture and technology based on a few drivers:
- Support any kind of activity.
- Flexibility of points recalculation at any time.
- Provider-agnostic.
- Real-time updates.
- Node.js- and AWS-based.
The second point was quite a crucial requirement because we wanted to rate each type of activity based on variable conditions. Let’s take walking, cycling and workout as an example. We based points for cycling and walking on distance, however, workouts are based on duration. Now, let’s add some more complexity to that equation.
One kilometre of cycling shouldn’t be worth the same as 1 kilometre of walking. It is far easier to cover one kilometre on a bike than on your feet.
So, we needed to move most of the calculation system from the provider to our system. Making it also less dependent on a specific integration however, it is not like we could use any provider. We still wanted to achieve real-time updates, so we had to make sure to have access to up-to-date rankings constantly.
💡 In this project we've used React Starter kit, our original solution. Here's more about it!
What is Data Lake?
Therefore, we started with a simple idea of how we would like the system to work.
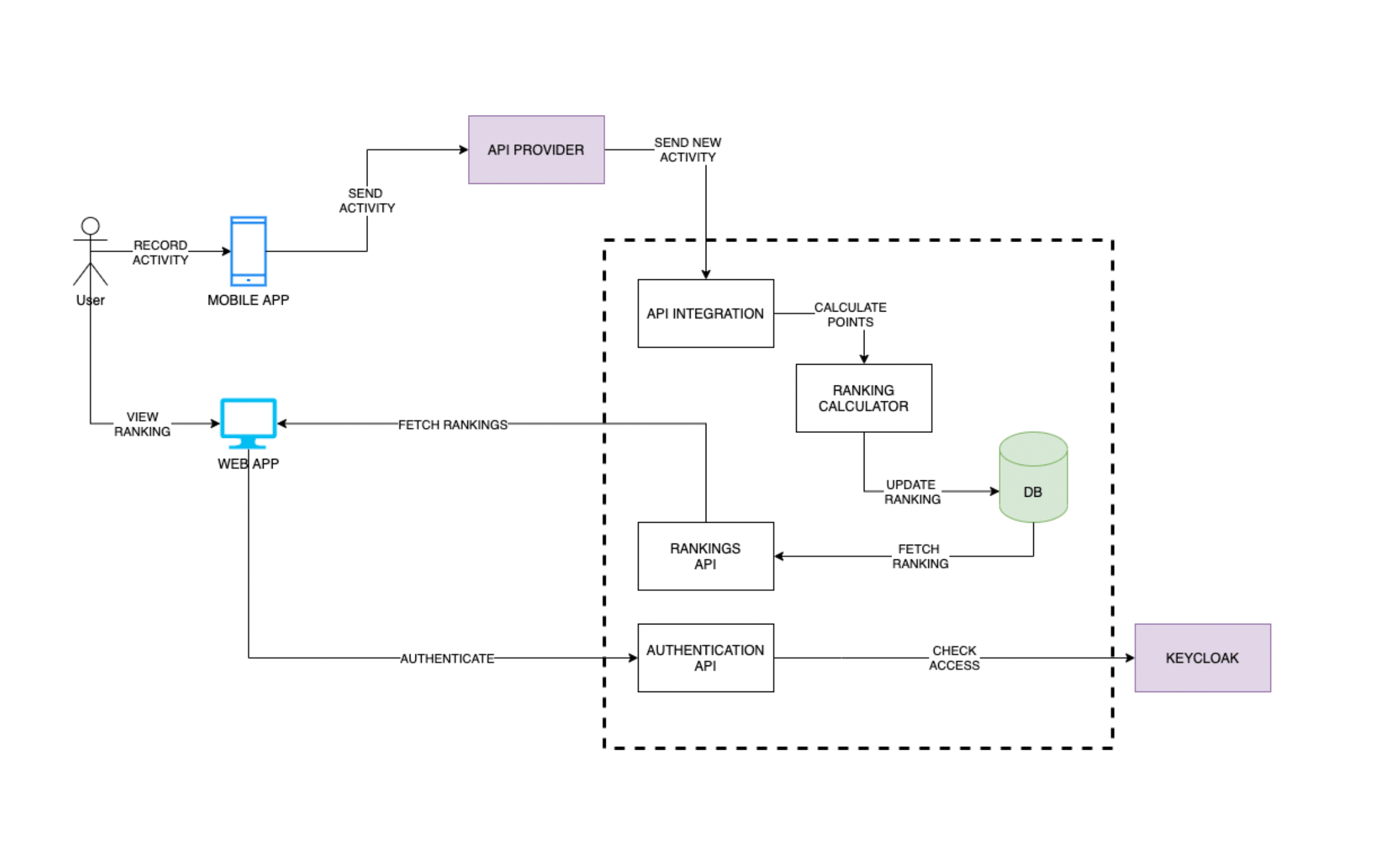
Based on that and our drivers, we started looking for a provider that had a mobile app and push-based API and we went with Strava. They’ve got a pretty nice API and webhooks functionality, so we could finally achieve almost real-time updates in our app. However, this time we needed to store the data and build rankings on our own.
To fulfil the first and the second drivers of our architecture, we needed to decide how the data is going to be stored and how we’re going to approach ranking calculation. Usually, we get the data from an integration, parse it, create some models based on that and save it into the database. We don’t store the original information, we only save a processing result.
This approach would work for most applications, but it has one big flaw. You need to know what information from the source data you’re going to use, so you can create a model based on that. Once created, there was no way to rebuild that model (at least not easily), because we had no original data. So shall we save the source information? Yup!
We aimed to gather the data first and then figure out what to do with that. Of course, we didn’t want to save everything, only information from services we’re interested in.
What’s more, we didn’t need to split the information based on a source. In fact, we could save Strava API information and some analytics data from our app usage, we could even add additional providers. All of those to be put in a single storage. No models, no schemas.
Those are the foundations of the Data Lake approach. Gather the data you need in a single space first and only then think what you could do with those.
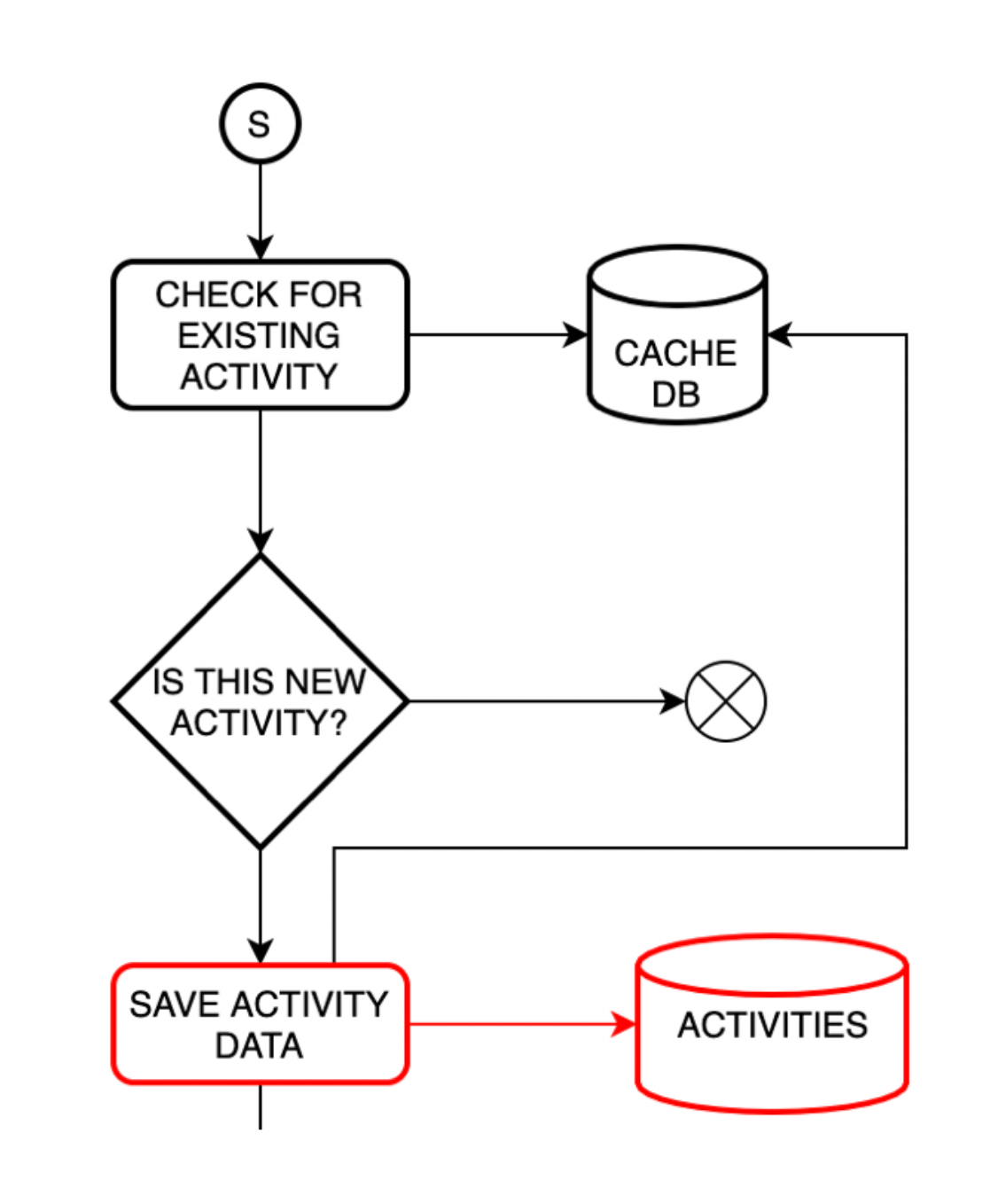
Obviously, we needed a little more to make use of that information. We needed to catalogue them – add additional metadata based on the content of information, so we know which of them to use for specific operations.
We could imagine having multiple catalogues in our app. We could even create one based on a year/month/week/day of activity based on user-based activities catalogue, activity type-based catalogues. With constant access to raw data, we can decide how to use them at any point in time. If in two years we decide we need to gather all users who travelled more than 10k kilometres… we could create a catalogue for that too.
Yet that information is completely useless when it comes to the presentation. So far, we haven’t calculated any ranking. So how did we tackle that? We could use CQRS-based architecture.
CQRS (aka Frontend vs Backend needs)
CQRS stands for Command and Query Responsibility Segregation. CQRS has two main components.
The Write side – a model made for keeping a source of truth. The information the backend needs to work. This component is also used to build a Read side of CQRS. If we follow this rule, the Data Lake is our Write Side.
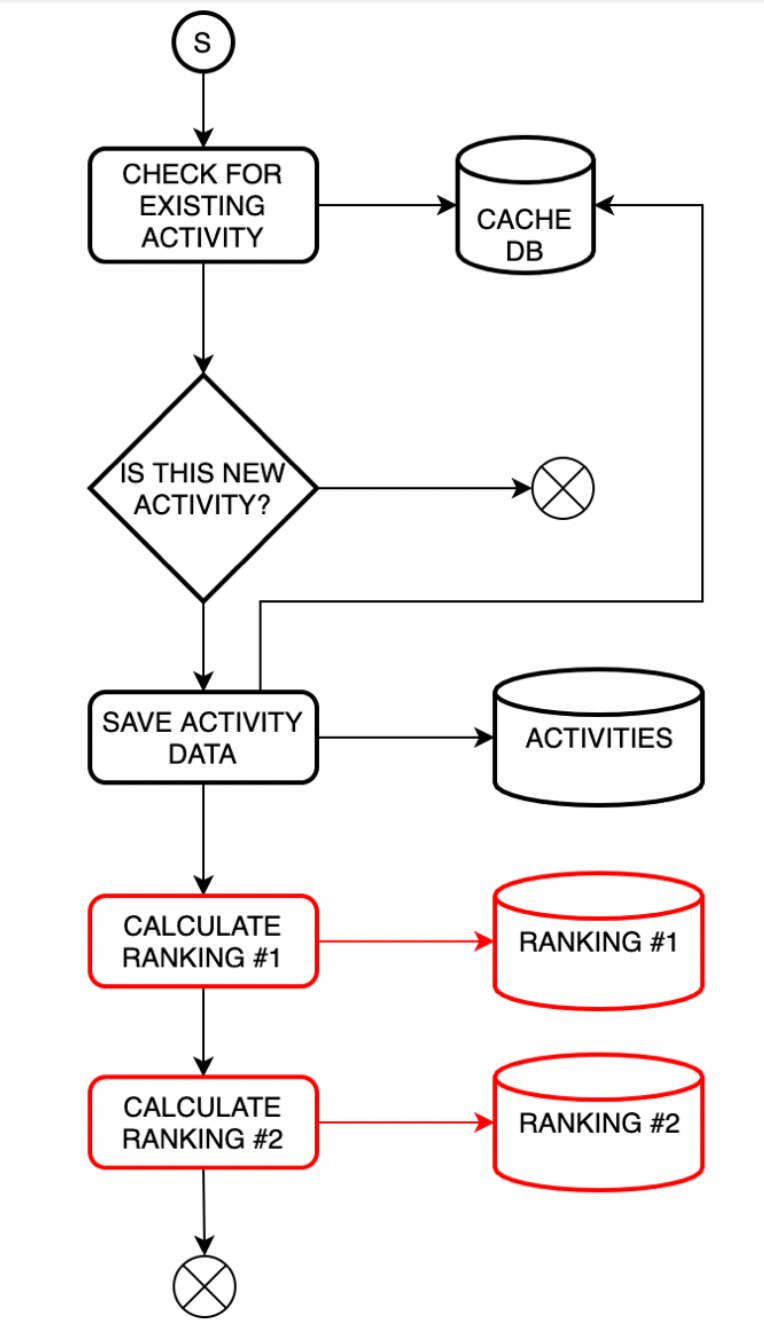
What we’re going to do is to save information in a data lake, catalogue it and then push it to a processing engine, responsible for calculating the points and updating the rankings. Both of those are a part of the Read side.
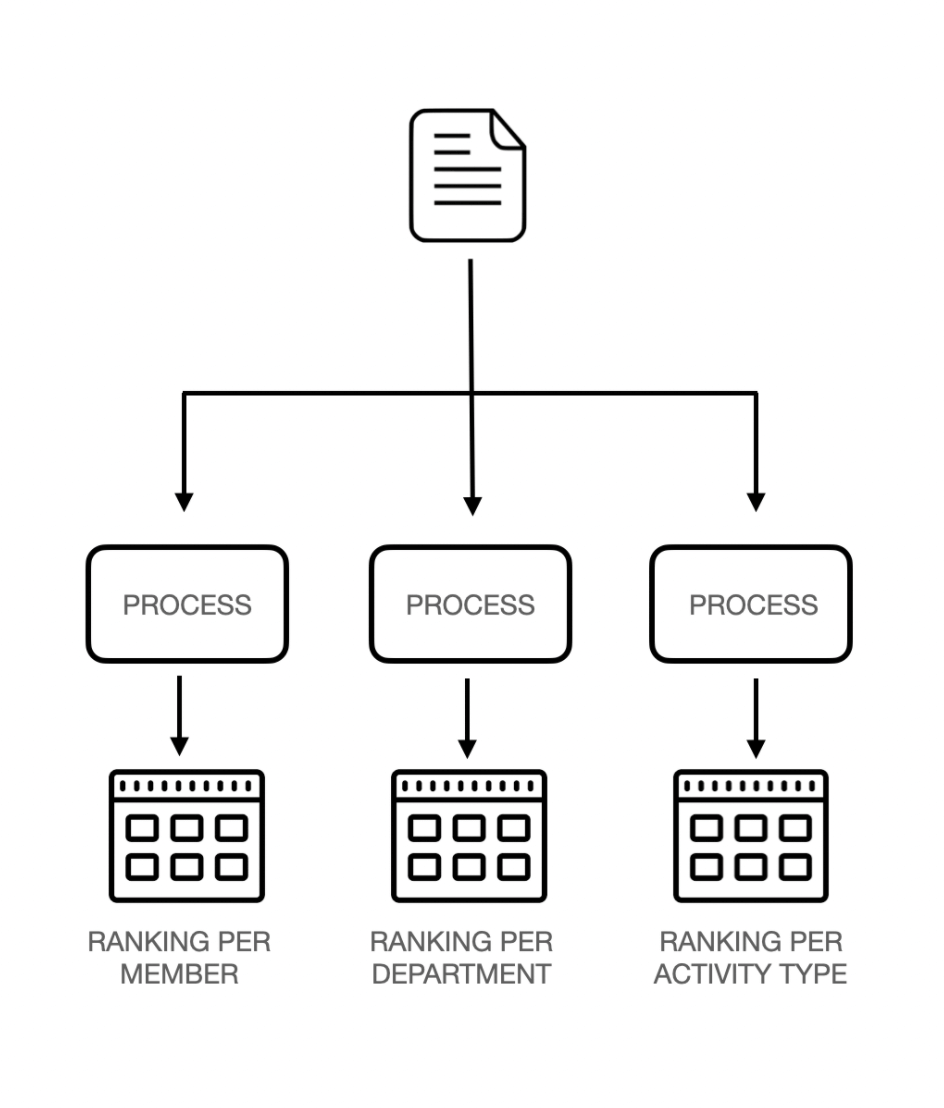
The Read side is always made with Frontend in mind. We model the data after frontend needs, so they can get exactly what they want. In our case, those are specific rankings – by a user, by activity type, total points gathered by the whole company or TSH departments’ ranking.
If we need a new one, we could just create a specific data processor, push data lake information through it and after a while get the results for a web app.
So how do we build this whole pipeline? Let’s use AWS for that!
Workflows with AWS
We decided to go with a Serverless approach and since we focus mostly on AWS, we went with AWS Lambda. This approach allowed us to reduce the costs. However, there is a challenge with it. Tracing the communication between multiple lambdas is hard to debug.
We could use an X-Ray to somewhat solve that problem, yet it will still be far from perfect. That’s why AWS introduced Step Functions. A service that allows us to create a state machine, where each state is represented by a single function. What’s more, we have a visualization of it in a form of a diagram.
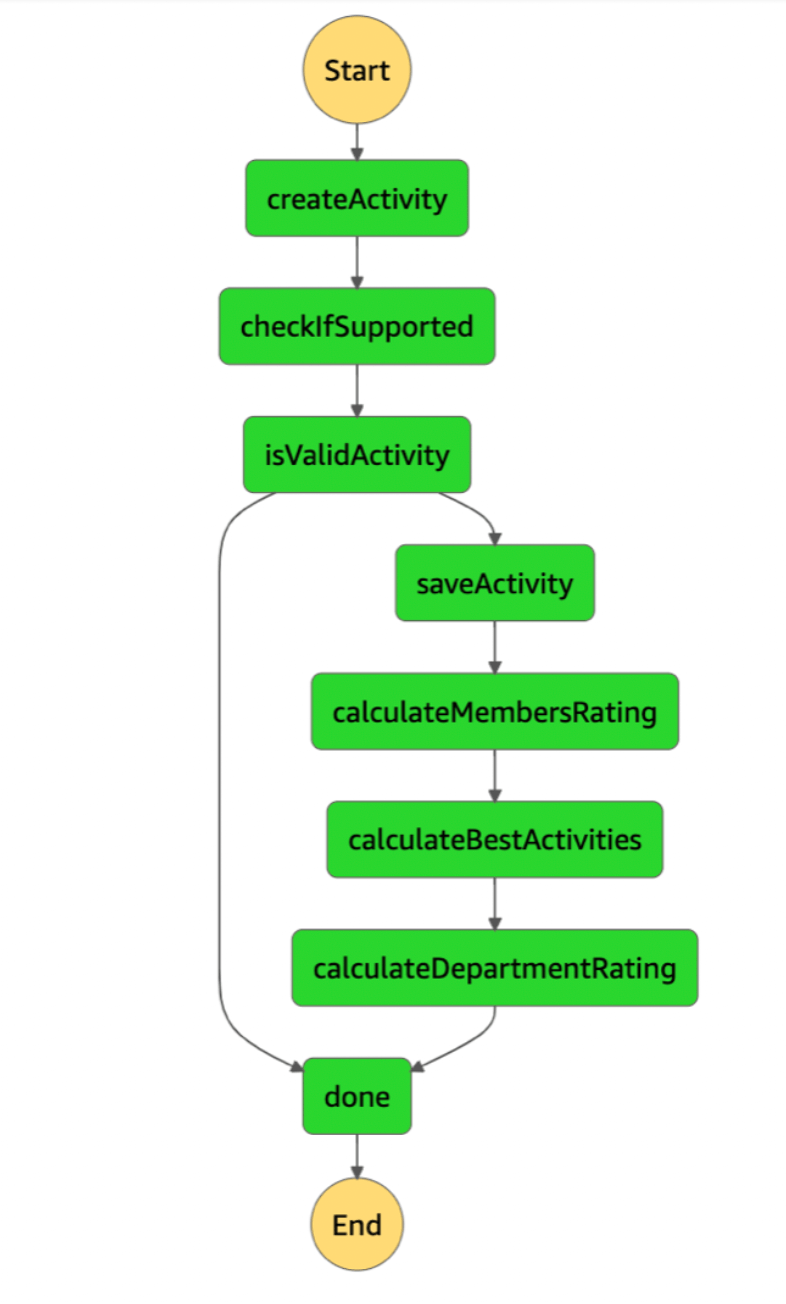
Of course, it is not the only benefit of that service. The biggest advantage is the execution panel. Basically, I can go through each execution of a workflow.
 For every execution, we see the diagram of our state machine. The green blocks represent the successfully finished function and the white ones – those that weren’t executed at all. We have access to the logs of specific lambda, so we can see the details.
For every execution, we see the diagram of our state machine. The green blocks represent the successfully finished function and the white ones – those that weren’t executed at all. We have access to the logs of specific lambda, so we can see the details.
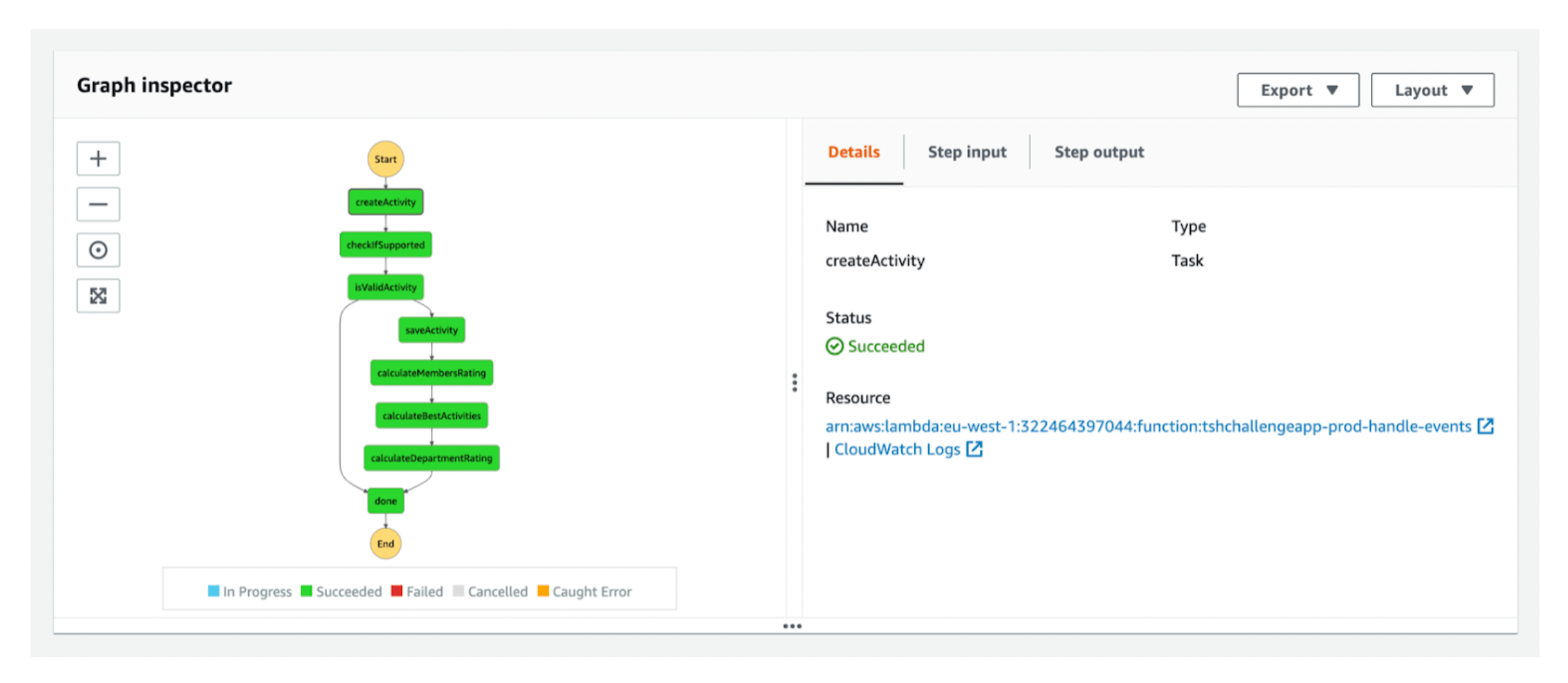
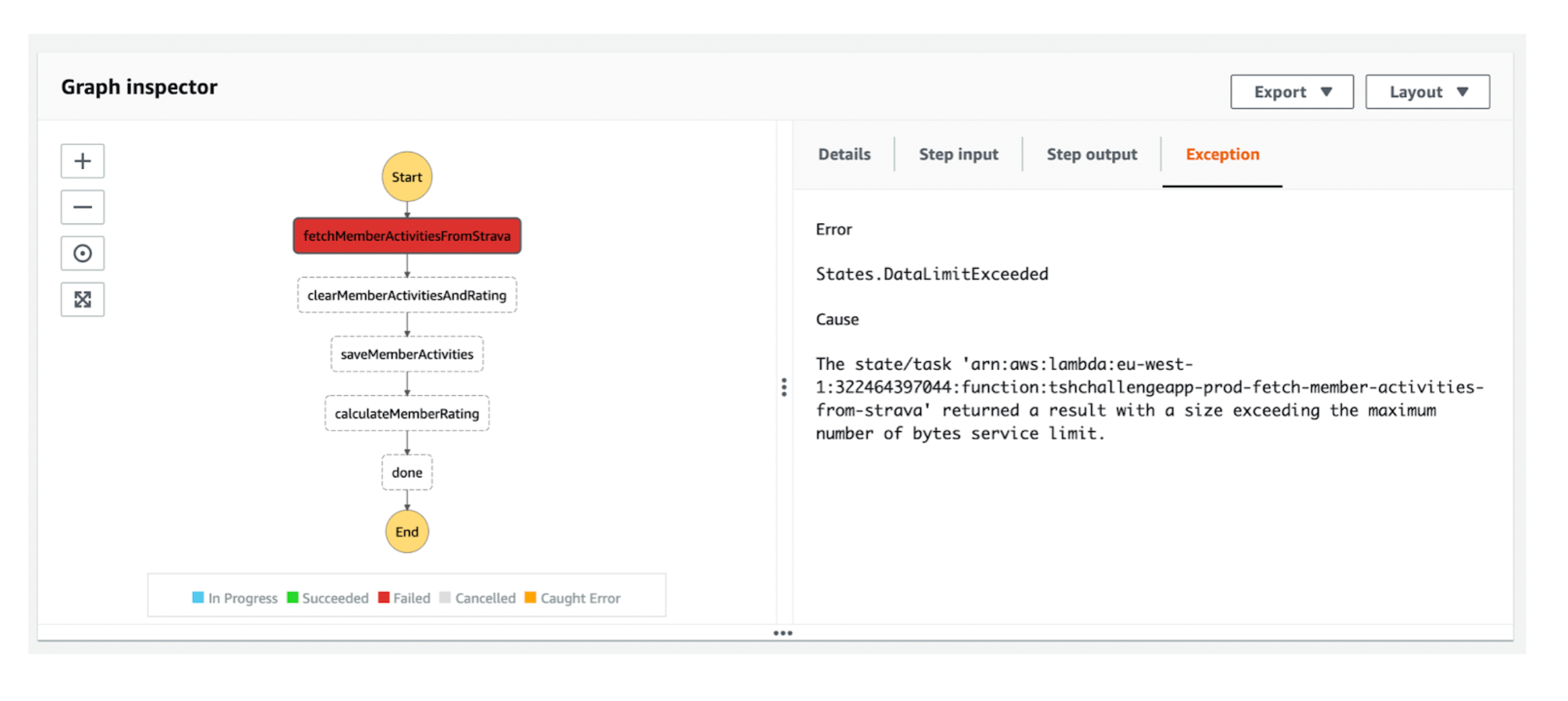
We could also check input passed to that function, so we know how to reproduce it. In fact, we can even re-run the same function after we deploy a fix.
And lastly, we can easily see the reason for failure.
💡 Make your own DYI serverless app:
Conclusions
TSH Challenge started as a simple idea, yet it evolved into much more mature architecture. The combination of Data Lake, CQRS and Step Functions allowed us to focus on the features we need, instead of a technical challenge. Every time we want to change the business rules, we are not afraid to do that, because we know we can rebuild the whole ranking system at any point in a matter of a few minutes.
At the same time, we still have a great development experience, because of serverless architecture. Each new feature is either a single lambda or a step function. Developers are responsible for the deployment, making it open for rapid development.
What more do we need? 😄
Find more practical articles for developers like this one in our TechKeeper's Guide newsletter.
It’s a bi-weekly publication for all the CTOs and tech managers interested in modern software development.

