15 February 2023
Data migration process that future-proofed the business strategy of Pet Media Group and contributed to increasing their revenue by 400%




Contents:
The Software House team was chosen to create one online platform to rule all current and future marketplaces in Pet Media Group’s ecosystem. One of the biggest challenges we faced was designing a data migration process that would move millions of records without losing data integrity or any of the marketplaces going offline. Check out what solutions we tried, what failed, and why we eventually set on ETL.
About Pet Media Group
Pet Media Group (PMG) was first a friendly initiative to find shelter for homeless animals. Gradually, it transformed into a marketplace network for animal lovers available internationally. After a series of serious funding and acquiring platforms like Pets4Homes, Annunci Animali, and PuppyPlaats, PMG was turning into one of the biggest animal marketplaces in Europe. Soon, PMG planned more acquisitions but then the mundane, technical problems appeared – each platform would have to be managed separately, which was unacceptable for the effective operations of the system as a whole.
Business background
The team behind PMG came to The Software House because they needed a technology partner to make their business plan operational in advance. They wanted to build an interconnected ecosystem of websites and applications that would unify all already acquired and future brands under one roof. The business idea was great, however, the implementation is a different story.
The main problem was that some of the platforms were technologically outdated, and all of them differed in the tech layer. Therefore, maintaining all of them simultaneously would be almost impossible, or extremely expensive. PMG would have to hire developers with different knowledge, skills, and experience.
The Software House was chosen to work on a single, modern platform to which all European marketplaces would migrate, which included:
- designing a mechanism for the data migration process,
- unifying functionalities,
- adapting each platform to individual markets characteristics (language, legal requirements, etc.),
- sorting out scalability issues,
- future-proofing the platform for possible new additions.
In this article, we’ll take a closer look at one element of the project – the data migration process.
Main focus – data migration process
The clients wanted the data migration to be carried out without shutting down any of the acquired marketplaces. This posed a significant challenge in terms of data integrity. Why?
Let’s say a user is publishing an ad to sell their puppies, exactly at the same time as data is being migrated to the main system. Data migration is still underway when the user notices a mistake in their ad, so obviously, they go and edit it. Unfortunately, there is a chance that the migrator has already moved that particular ad before it was changed, so the update won’t show there
Now imagine this scenario with millions of users and records. It’s a massive risk for data integrity, and we couldn’t have that.
What did the data migration process look like?
Data migration is a multi-stage process. For the PMG project, we’ve established the following path:
- Analyzing the input and output diagrams. We look for differences and mark places for discussion – e.g. potential lack of some data.
- Determining how to fill in these blanks. What information and from what source do we provide there?
- Preparing a migrator prototype. We use a few pieces of data to test-run the migration on a certain data scale. This helps with estimating the time needed for full migration.
- Analyzing the test results. This will determine how the data migration will be carried out and what will be needed from the main application page (e.g. temporary maintenance).
- Performing a dry migration. It’s a verification of data integrity, and it’s crucial to see if all data is correctly migrated.
- Running the actual data migration process on the real platform.
Alright! Let’s get to the nitty-gritty.
What technological solutions did we consider?
Pet Media Group came to us with a very specific problem – they have the current platforms, which in the future will act as a base for other local shops joining the ecosystem. We had to be prepared that each marketplace would have different features and ways of maintaining it.
The easiest way to solve this is to share the codebase (so that once a bug is fixed it is fixed everywhere) and a common data schema so that every platform has the same data structures.
The biggest challenge was transferring data from the existing service to the new platform – especially since we are talking about platforms with hundreds of thousands of records each.
First data migration plan – failed idea
In the beginning, we considered flow like this:
- First, we make a backup copy of the current database, put it on a separate server (or we create a so-called read replica, in this case, an additional database, next to the main one) from which we can load data for migration without straining the proper database. This way, there won’t be any disturbances for the users of the current site.
- Then, we use this database to perform the initial data migration.
- Finally, just before go-live, we either enter the maintenance mode or assume that there is little data left to migrate (current data minus the originally migrated data) that we don’t have to run maintenance because the server won’t be overloaded (specifically, the database, which feeds it) and run a differential migration (DIFF) and align the target database to the present state in the source database.
In fact, the DIFF migration was supposed to be launched just before switching from the old site to the target site, so maintenance mode would have to be launched anyway. We also assumed that for whatever reason the period between the initial migration and go-live might be extended, so then we might want to run some intermediate DIFFs (intermediate diffs could also be run from a replica/copy of the database), hence the assumption that there may be no need to maintenance mode.
The two biggest issues when it comes to resuming a migration from a specific point (or a DIFF migration) are figuring out where we left off our migration and how to map the migrated data to the source data. Therefore, these types of migrations are heavily dependent on the source data.
For example, if a table that we are migrating doesn’t have an id column that determines that exactly this record was moved as the last one, and additionally, there is no column to sort the data in a repeatable way, then without changing the source data schema it may be impossible. In an ideal world, the source data has an id column that allows indicating exactly the last migrated record, and columns describing when the record was created (created_at) and last updated (updated_at).
So, we needed a DIFFrent idea.

Chosen solution – Extract Transform Load (ETL)
Our thought process led us to the conclusion that extract transform load (ETL) is our only hope. It’s a system to convert one database schema to another:
- E – extract – extracting data from the source,
- T – transform – transforming raw data into a form that allows you to work with it,
- L – load – sending the processed data to the destination.
However, ETL came with a few struggles.
Problem #1 – the old marketplace keeps adding data
A couple of solutions are available here. You can use systems synchronizing data in real-time (if something appears on the old marketplace, it is immediately transferred to the new platform), or you can switch to MT mode in the old marketplace for a certain period and run the migration.
In our case, we examined two data migration tools: AWS DMS (Database Migration Service) and the MT mode. DMS allows you to synchronize in real-time, which is an amazing benefit, but in our case, some data had to be supplemented by making queries to external services, so we decided to go in the direction of MT.
Whichever option you choose here, more problems arise.
Problem #2 – data is incomplete
A typical ETL should be preceded by a very important analysis phase. Learn from our mistakes – we could have avoided A LOT of issues if we spent more time on the initial scheme analysis. Eventually, it really made a difference.
You compare the input schema (old system) and the target schema (new system) and figure out what to convert. If you’re able to map everything 1:1 then you’re all set. Unfortunately, very often it turns out that a field in the new scheme doesn’t exist in the old one, and you need to establish rules deciding what and how should be completed.
Problem #3 – you may need to restart the migration
It’s very important that data migration is:
- idempotent – if you upload the same set of information to the system, it will be duplicated and there will be no error that such information already exists. Just nothing will happen (or crash) and the system will be coherent.
- possible to resume from a specific moment – resuming import from a given point in time is crucial in modern systems. Imagine if you had to run a 5-day operation and an error occurred on a single record on day 4, and because of that you had to start all over and wait another 5 days again. his really made our blood boil because we underestimated how much data there is in the old services.
Now for the ETL…
How did we adjust ETL for data migration in the PMG project?
How genetically does such an ETL works? Data is fetched from source X, transformed to match the target schema, and added to the database.
What is specific to PMG data migration?
In order to ensure that all data will be migrated correctly with no loss to data quality, we’ve established a data migration strategy for PMG that can take place in several ways, and in several different modes.
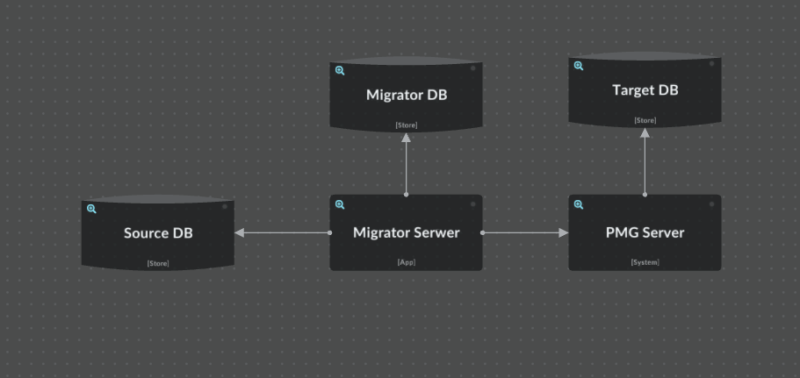
Currently, the “normal” mode is active, let us tell you how it works:
- downloading data from Source Data Base (database of a new marketplace being added to the ecosystem),
- mapping data to an acceptable structure specific for PMG Server,
- saving the mapped data in Migrator Data Base,
- uploading mapped data to PMG Server,
- PMG server checking if the data has appropriate structure,
- YES: data is saved in the Target Data Base.
- NO: the Migrator Server communicates to the Migrator Database that it failed to transfer the rejected data correctly.
- end.
The data is migrated in the correct order defined by the developers, based on the initial analysis of the data structures in the source and target databases.
For example, we usually migrate users first before we migrate their listings because the user is the “parent” record of the ad, so needs priority.
If a record has not been migrated correctly, you can browse Migrator DB and check out what it looked like originally, and what error occurred during its migration.
Additional modes
We’ve mentioned before that the currently active mode of data migration is called “Normal”. However, there are also four additional modes prepared specifically to solve the business requirement that the new marketplace in the ecosystem must be functional during migration:
- “Diff” – migration of data that has changed during the process,
- “LocalDiff” – migration of data that has changed only locally
- “RetryFailed” – re-migrating data that previously failed
- “FindMissing” – entering missing data
OK – so what good did all it do?
Benefits of this data migration process
Data migration is done to unify the scheme so that the platform and the entire ecosystem are easier to maintain. Therefore, the main goal of Pet Media Group was to simplify the maintenance and software development of many marketplaces from the same industry. They wouldn’t be able to operate on separate code bases, different technologies, or types of databases. Which meant no data migration = no platform launch.
Thanks to the new data migration process, one person can immediately check and fix errors in any marketplace in the ecosystem. What’s more, a single platform means that a new improvement in one marketplace is an improvement across all marketplaces.
More benefits for the project:
- ZERO downtime events post-migration,
- data migration doesn’t take more than a few hours, and we’re talking 5 million customers each month,
- PMG was able to swiftly add a lot of new features across all marketplaces (e.g. chat for customer queries that improved their customer service),
- the established process is future-proof, which means it will be used in the takeovers of new marketplaces,
- thanks to the uniform technology stack PMG can focus on working with a single technical team that’s finally responsible for all marketplaces connected to the main platform,
The data migration process contributed to the overall platform launch and had a direct impact on the company’s revenues growing over 400%!
The client quickly felt the positive impact of cooperation with The Software House.
Customer feedback
We’re not going to lie, our entire software development team loved our cooperation with Pet Media Group, and we think that the sentiment is mutual. Just look at those glowing reviews!
🚦 Disappointed with your test results?
You could redo your observability setup or even make a decision to migrate to a new system if yours has significant technical debt. Learn how you can move forward with the help of an advanced cloud engineering team.
To sum it up – data migration can drive business value
Building a brand from scratch in various countries is quite difficult and time-consuming. In order to speed up this process, Pet Media Group came up with a brilliant idea of combining local marketplaces with an already established reputation and customer trust into one platform for selling and buying pets and animal accessories.
This is a great added value for PMG – maintaining one platform with one software development team is easily manageable and far less expensive than working on many local marketplaces with remote teams operating on different technologies and tools.
Now, the client has a universal set of tools for relatively quick migration of subsequently purchased marketplaces. When a new marketplace is added to the PMG platform, data is effortlessly migrated there as well. After the data migration process, the PMG platform is launched in place of the acquired marketplace. Simple as that.
Future goals – observability enhancements
Now that the entire system is unified following a successful data migration that contributed to a 400% revenue increase, the client can build new observability processes from the ground up. The simplified structure of the system will make it easier to collect and process data efficiently. The new observability scheme will serve two main objectives:
- preventing errors and downtimes,
- powering Business Intelligence efforts with timely and focused insights gathered in custom dashboards.
As part of the implementation, we’re going to move logs from AWS CloudWatch to Grafana for easier filtering. The system will collect both technical and business metrics, including detailed information about payments.
It looks like there is still a lot to be done, but for now – hooray for technology solving business problems!

