02 June 2023
Migrating from monolithic to microservices: a practical guide


The web provides many answers in the “Monolithic vs microservices” debate — except how to migrate onto the microservice architecture in detail. From this guide, you’ll learn about the differences between monolithic and microservices, how to prepare your app, and what you should do at each transitional stage. Strap in!
There are a lot of articles that consider migrating from monolithic to microservices architectures, but few of them provide enough practical information to really get a feel of how it is going to be.
Well, this article gives you an entire legacy monolithic application complete with code and walks you step by step by the thought process that goes into moving it to microservices.
What you will get:
- A full insight into what’s wrong with the project and its existing functionality and why a decision was made to switch from a monolithic system to microservices.
- A full list of actions that need to be taken to make the move from monolith to microservices happen.
- Best practices of moving to microservices in the context of that mock project.
- A dive into data management involved into that kind of migration, including a lot of legacy data related advice.
- I will also talk about adding a new functionality to the system, existing data interactions, data integrity, software architecture and more.
What you will take away:
- Why and how companies really move to microservices.
- What kind of problems such a migration solves and what problems it creates.
- The services, tools, and techniques used in migrating from monolithic to microservices.
Let’s go for it!
Migrating from monolithic to microservices – project specification
Let’s imagine that you are assigned a new project. You have to talk to your client and gather all the necessary information. You make an appointment, speak to the client and collect the notes to outline a domain of the project.
Assume the results look like this:
- In the project, you’ll work on a platform with live updates for football matches
- The administrators have the database of teams and fixtures, and they provide the reporting
- Only logged-in users have access to the commentary
You were told that the application’s development continued for a few years, but it’s challenging to implement any improvements.
Developers from the project complained about the growing technological debt and the code quality.
With access to the repository with the code, you found out that the client’s application uses a framework. The business logic is wrapped by services that are injected using dependency injection.
The app threats controllers as services to simplify the logic and use the same injection method. Finally, everything is tied together with autowiring.
REST API with the JWT authorization receives all the communication.
The client is concerned with two main issues — the shaky development process and the app’s inability to handle heavy traffic. But before you save the project, note the client also wants for code readability to improve significantly.
Development tips to keep in mind
The first thing to do is to clean and refactor the app with no major changes to the architecture. There are some elementary rules you should follow.
- Always perform small changes and test the app’s functionality afterward
- When performing changes, don’t add new functionalities
- Revised code should be more readable after changes
Remember you can’t implement proper changes without recurrent testing. If there were no automatic tests introduced before, unfortunately, you’ll have to write them from scratch.
Even if there were some test scenarios written already, check if all the significant parts of the app are covered.
Need to add any new tests? I recommend that you only perform the high-level ones — some parts of the code and functionalities will probably change, so Unit tests are not that important.
💡 Also see
Cleaning up the code before migration
Focus on the code that is long, duplicated, or messy. It’s essential to inspect long classes in which the number of code lines comes in thousands.
Make sure you analyze all the comments which try to describe over-complicated logic. Note that functions and variabilities should be named in a way that’s self-explanatory for the sake of clean documentation.
Look for repeating fragments of code scattered around the app, code that’s dead or writteng “just in case” (YAGNI break), long lists of parameters, and extra class constants and variables.
Further down, drill into how the classes behave. You should check if:
- Methods use the data from other data objects more often than their data
- There are any call chains that make code dependent on the structure of a particular class
- Classes, which are not the implementation of patterns, such as strategy or visitor, have two-way dependencies
- Methods in classes used only to induce other methods which are not an implementation of a proxy pattern
- The functionality of several classes depends on each other which don’t use delegations or composition
Those are just a few examples of so-called Code Smells that you can find in code.
If you’d like to master code cleaning, read the excellent book called Refactoring: Improving the Design of Existing Code by Martin Fowler.
So, how you can use the theory in practice?
Let’s focus on one of the controller’s methods, called FootballMatchController::editAction, that allows you to edit the football match information ().
There’s a lot happening in the body. The application checks the access to the endpoint, prepares a query object, performs validation, updates a match, and returns its current state.
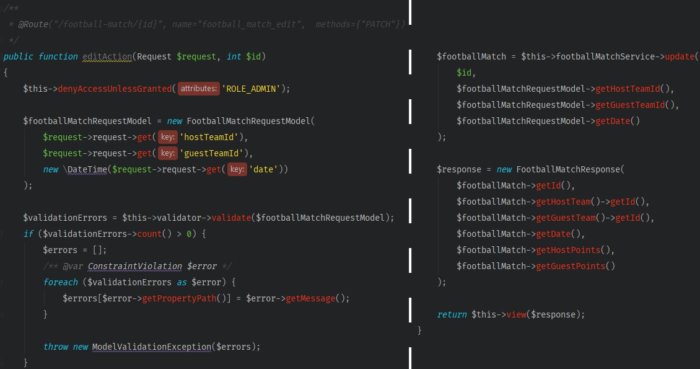
Looking at the method, you can quickly spot a few schemes.
- The creation of the request model happens every time the request is sent to API, working the same way for a variety of endpoints
- The scheme for editing or creating a resource needed to go through the validation process repeats for each method
- Getting the teams’ IDs requires a reference to another data structure
- Lists of parameters are long, and in most cases, you get the data from the same object
Fixing those shortcomings shouldn’t be that difficult. Most often, code fixes will be about moving logic to suitable classes or adding a new method.
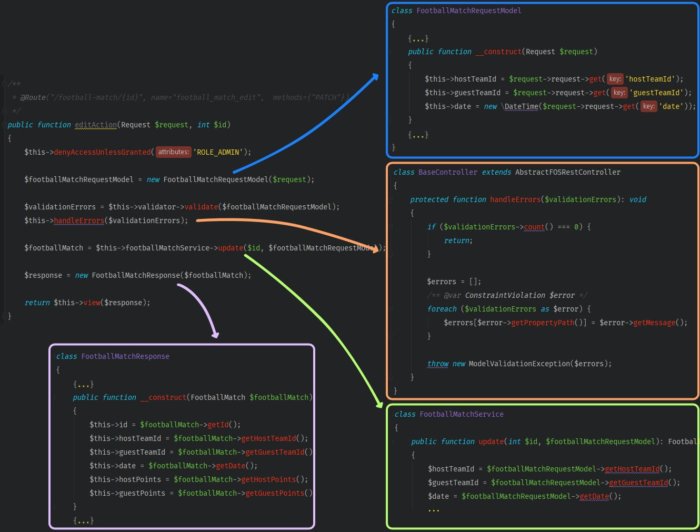
To clean up our method you should:
- Modify the constructor of the class
FootballMatchRequestModelso that it takes a Request object as the only parameter - Create a base class for controllers and a method that will handle validation errors inside.
- Shorten the list of variables of the method which updates the events service to the ID and
FootballMatchRequestModelmodel. - Use the whole event rather than a long list of the fields to create the object
FootballMatchResponse
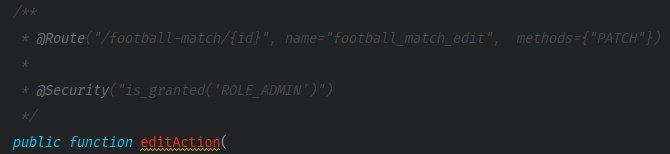
In our project, we worked with Symfony. Of all the modules, I picked FOSRestBundle. The first advantage you can use is Symfony’s Security component, which allows you to define the access to the method in controller using annotation.
Another simplification that you can introduce would removing the multiplied manual creation of the request object scheme.
Only the data will be later verified in terms of correctness to make sure you can use it safely in other parts of the application.
Luckily, the creators of FOSRestBundle enabled automated attribute filling of the indicated object. What’s more, they allow running a validation process for the supplied model.
This option isn’t enabled by default. That’s why, if you want to use it, you need to apply some changes in configuration. There are, however, only a few more lines of code to be added.
💡Study: FOSRestBundle documentation (Validation)
In the method’s comment block, you should find annotations for @Security and @ParamConverter.
@ParamConverter needs the addition of extra method parameters to work correctly: a model to the app uses to convert data and a variable that contains the list of potential validation errors.
So far, your actions would have slimmeddown method’s body, leaving only 4 lines (out of previous 40!).
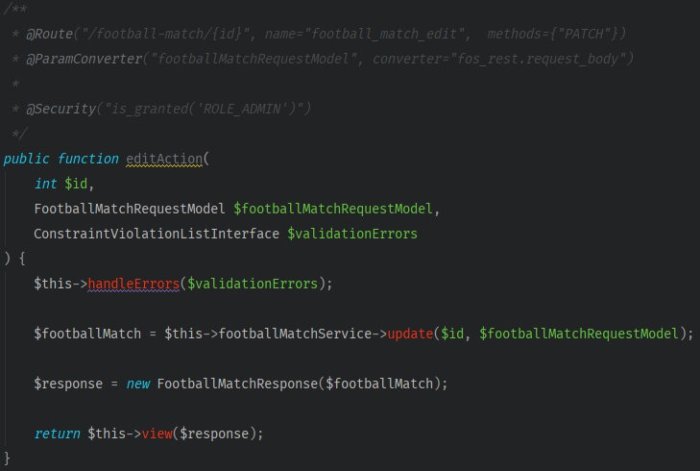
As you can see in the app controller fragment above, you can transform code quality with some straightforward refactoring techniques.
From now on, whenever you change anything in the application, you won’t need to look through the entire project to fix all the duplicated code fragments using a particular class or method.
🤔 How skilled is your company at using data? Try this 5-minute test
Both a monolithic and service-oriented system can be efficient. But to make sure it is that way, you need to measure performance indicators. This test is an easy way to learn how well your organization uses data to do that and much more. 5-10 minutes & no registration needed. 👇
Architecture transition phase
It’s time for architecture remodeling. Take “baby steps” I mentioned before to avoid crashes caused by radical edits.
Introducing a transitional structure between the monolith and microservices will help you rebuild everything at minimal risk.
We’ll depend on a concept called Bounded Context, which is derived from the DDD (Domain-Driven Design) methodology, that helps divide a complex business domain into smaller contexts.
One of the essential assumptions here is that all the context’s boundaries must meet a specific restriction, as contexts can’t affect processes that happen in other contexts.
💡Study: Bounded Contexts
But how can you split a domain into contexts?
Unfortunately, neither DDD nor Bounded Context reveal the secret, so we’ll go DIY.
Let’s scan the business domain to figure out what kind of a coherent group of behaviors or data sets occur there naturally.
Our client’s project has the following contexts:
- User context
Administrators and registered users of the platform
- Teams context
A list of the teams available in the app - Events context
A game between two teams that takes place on a specific date - Commentary context
The reporting of the football matches
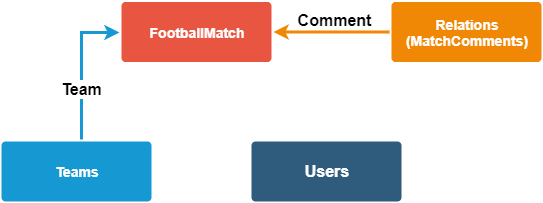
Doesn’t it look a bit like microservices at that point?
Another architectural pattern that is often used alongside Bounded Context is called Command Query Responsibility Segregation (CQRS).
The pattern’s role is to separate the responsibilities of methods that represent the intent in the system (command) from methods that return data (queries).
To get a better understanding of this pattern, read a series of articles about CQRS and event sourcing implementation in PHP from one of my colleagues.
With the use of the CQRS and its reading and writing separation of logic, you will get short, specialized commands and queries in your code base.
Data classes and structures prepared according under the guidelines described here should have namespaces that correspond with the created contexts.
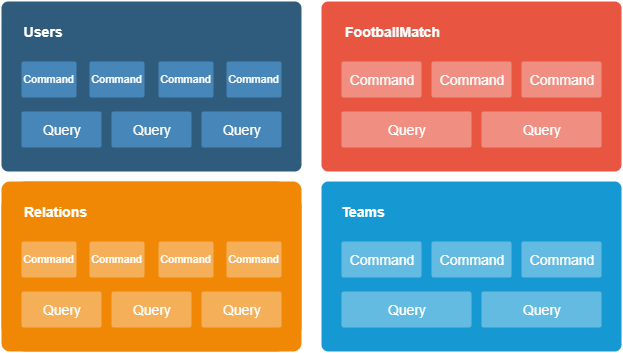
Knowing what kind of patterns you can apply, it’s time to think about how to adjust the codebase to CQRS.
Let’s start with the proper implementation of a part related to commands using the Tactician library . The group behind it aims to ease the implementation of a behavioral command pattern and its utilization.
You use three basic classes to work with the library:
- Command
Encapsulates input data
- CommandHandler
The reporting of the football matches
- CommandBus
Invokes theCommandHandlerconnected to an individual command
Now, we’ll set a method for editing planned matches, using FootballMatchController::editAction.
Before, you had to use a dedicated service linked to a match if you want to edit it. To use CQRS, the intention of changes should be enclosed in a command, and the editing logic should be in a proper handler.
Adapting to the new requirements, wrap up the data from the query object in one command. It’s just a simple DTO.
The app will push the command through the CommandBus to the handler class, which will then apply the logic connected to the update.
Review this example of how to modify the editing method and related classes.
- Create a command which will deliver all the data to a handler
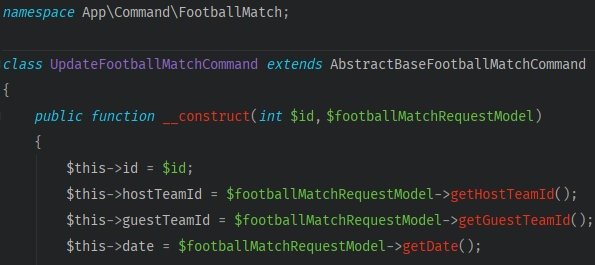
- Take the logic responsible for the event’s update out from the service
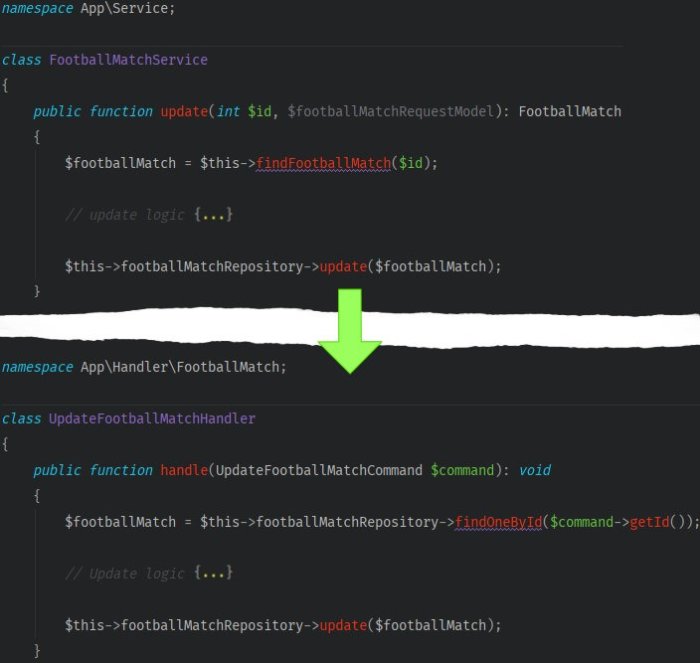
- Inject the
CommandBusinto the controller. In the body of the method, encapsulate a query model with a command. Then code the command to be passed for execution.
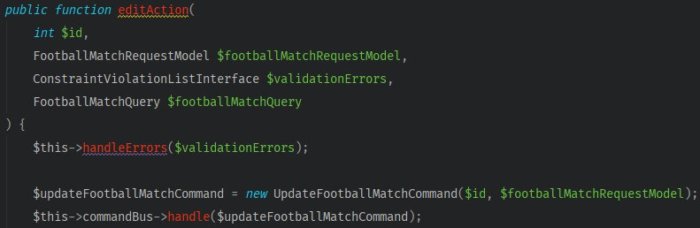
So far, everything has been going as planned! But now, there’s a new problem. The test of the method for match editing turned red.
In one step of a testing scenario, the app verifies the correctness of the returned data from the query sent to API. Before changes, the update method of the event service used to return the object of a particular match.
The problem here is induced by the command’s design as they don’t return data.
If you want to return the current state of an object in the response, you have to get it yourself. It’s the perfect moment to add Query — the second part of the CQRS pattern — to the app.
Query is like an interface that allows data access (CQRS equivalent of Repository pattern). The data returned from Query needs to have a proper structure, so you need to add View objects which will review the input.
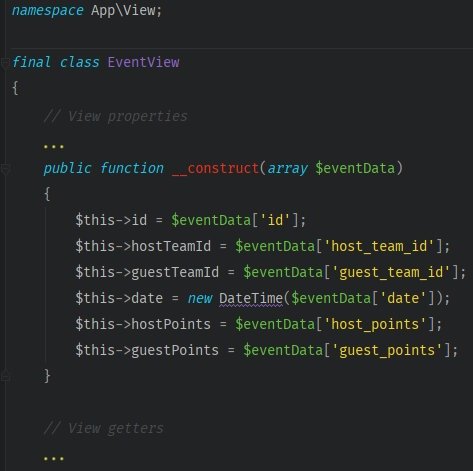
Let’s create a Query responsible for fetching the data associated with a match.
The class to work will require the object of a database connection. You can use the one from Doctrine’s database connection, which will give you access to the DBAL (Doctrine Database Abstraction Layer) query builder,
DBAL lets you create queries conveniently. But in our example query object, I did not use repositories because:
- A repository will add an unnecessary layer of abstraction and complicate the code
- The closer we get to the source of data, the lower overhead of Doctrine ORM, improving efficiency of the read operation
- Misusing functions of a repository can cause trouble
You should add an interface to the query. This will provide class interchangeability if you ever have to change the source of our data.
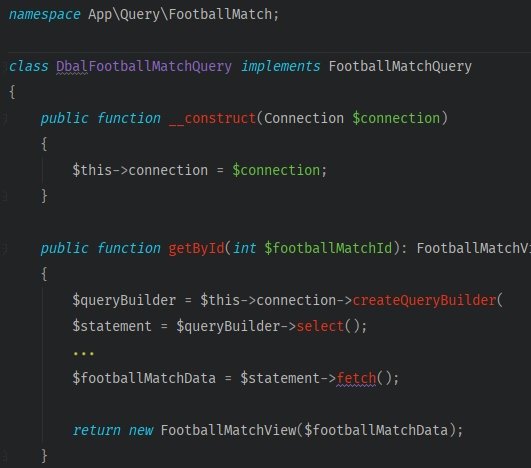
The last thing to do is to add and use the FootballMatchQuery inside the method that updates a match.
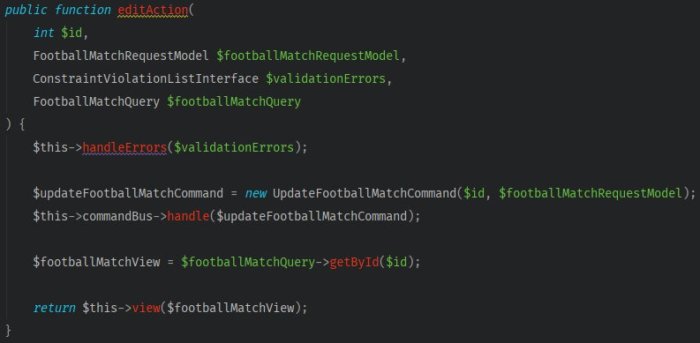
You completed event editing endpoint modification. The tests went green, meaning other API components didn’t stop working after our rewrites.
The code after all the changes presented above can be found in this repository.
The example above illustrates a simplified process of creating an intermediate architecture before transitioning to a microservice one.
This in-between state achieved using the proposed CQRS architectural pattern allows easier app maintenance and further development.
By implementing CQRS in the system, the project now has:
- A simplified models in the client’s domain
- A clear boundary between read/write operations
- The ability to present data easily with the use of different view types
- Improved change flexibility
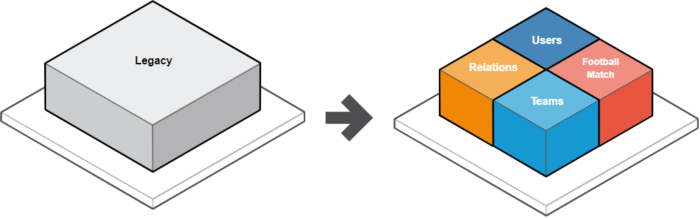
With some proper planning, it is possible to implement code changes in a few stages that won’t affect the elements of the system.
There is a possibility that a client will want to stop development after seeing benefits coming from migrating the app onto an architecture with the CQRS pattern.
The data flow inside the current system
We began with a refactor of a live text relations platform with code refactoring. Only registered and logged-in users can still access football games.
The CQRS (Command Query Responsibility Segregation) architectural pattern we added lets us read and write operations into the commands and queries. We also moved the logic to the corresponding namespaces.
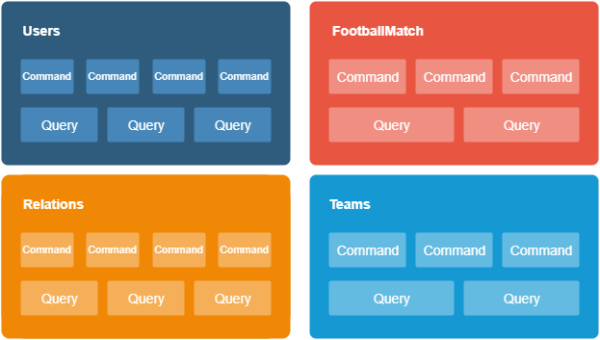
This repository holds all the latest changes to the code.
Before introducing architectural changes, please pay attention to the various actions performed in the code and how are they invoked.
Let’s review how the app handles a typical request.

Looking at the scheme above, you should that there is an additional data transport layer between the request (wrapped by the command) and the action handler.
The CommandBus, which relays commands to proper handlers, manages this transport layer.
Thanks to the CQRS pattern, there’s a segregation method available for reading or writing the data.
You could even feel tempted to disable CommandBus (don’t) to issue command handlers manually. You’d have better control of this transport layer mentioned above.
To make it even more convenient, you can implement our intermediary mechanism that matches the intentions with their execution. You could go a step further and incorporate whatever communication protocol you see fit.
And actually, I’ll help you create a similar solution later in this article, but we won’t ditch the usage of the CommandBus 😉
What communication protocols are available?
In a microservice world, the most popular ones are HTTP and AMQP. But you’re not limited to them.
Nothing prevents you from using, for example, binary protocols like gRPC. For this guide, I chose an HTTP protocol, and here is why:
- HTTP is a text-based protocol that is easy to debug and fix potential problems,
- It is readable, simple, and widely known,
- It does not require the installation of any additional dependencies to work.
Let’s replace CommandBus with an HTTP protocol in the previous communication scheme and logic handler with a microservice that will perform the same business logic.

This way, we will slowly start extracting the app’s logic from the old codebase into proper microservices.
This cutoff will happen on a level where we have definitions of each endpoint. Thanks to the context segregation done previously, we can move all related logic out of the old architecture almost in one go.
New system architecture
Let’s consider how to connect loosely coupled microservices together.
Depending on the needs or the project size, you can apply one of a few available patterns or their derivatives.
Nothing prevents you from mixing them together. Most of the patterns are derived from the way how they are connected to each other. We can distinguish a few patterns:
- Aggregator/Proxy pattern
Used to meet specific functionality or dedicated service (proxy) or client-side app (aggregator) calls for all individual services
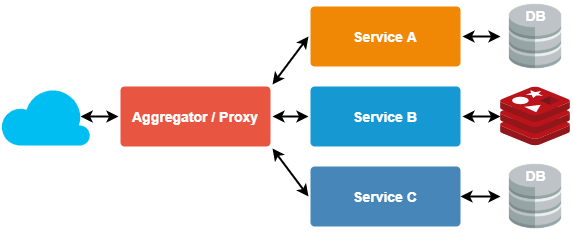
- Asynchronous message pattern
Useful for asynchronous calls in the system as HTTP communication is done synchronously. Using the AMQ message queue allows easy interservice communication
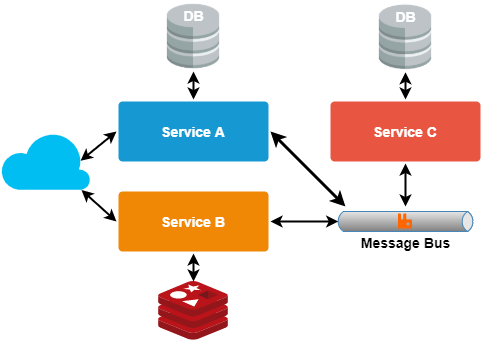
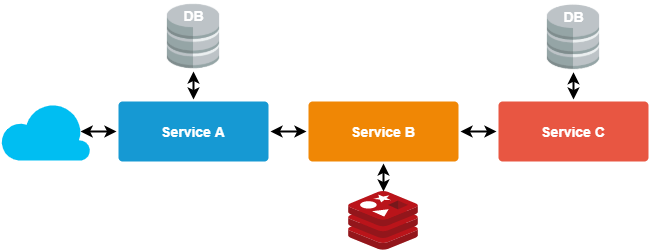
- Chain pattern
Used to generate one unified response from several dependent services, where the response of one service becomes the input of another subsidiary service
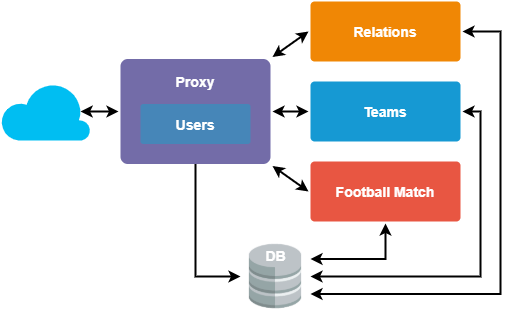
You should use a proxy pattern to keep the architecture simple. Let’s create one service created for that purpose.
This service will communicate with all other services, benefiting you in two ways
- A proxy will become a central place from where we will call all other services
- The process of the user authorization and authentication will get simplified
Why did I mention security?
Because authorization and authentication greatly affect architecture choice. Let’s imagine a simplified request done through a web application.
The user wants to fetch the entire football event (teams, relation,s and scores), but the app restricts access to registered and logged-in users.
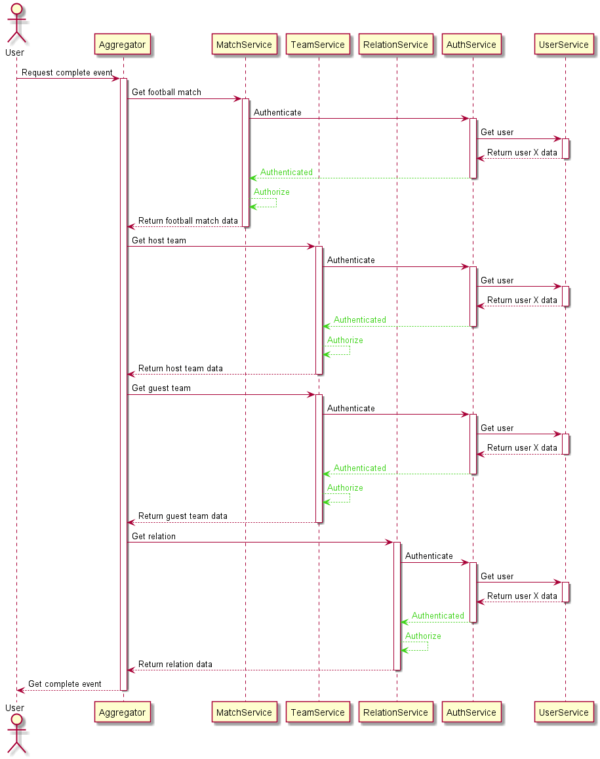
After the creation of multiple services that are exposed to users, we would need to pass a token on every request.
The services would authenticate us as using another dedicated service and then authorize our request. This practice would duplicate the same operation several times for no reason, extendiong the time to get a response from the application.
According to DDD methodologies and bounded context, the logic performed to get data from microservices alongside the authorization process can be included in the proxy.
The proxy will perform the authorization at the beginning of the process and fetch the data without having to repeat it.
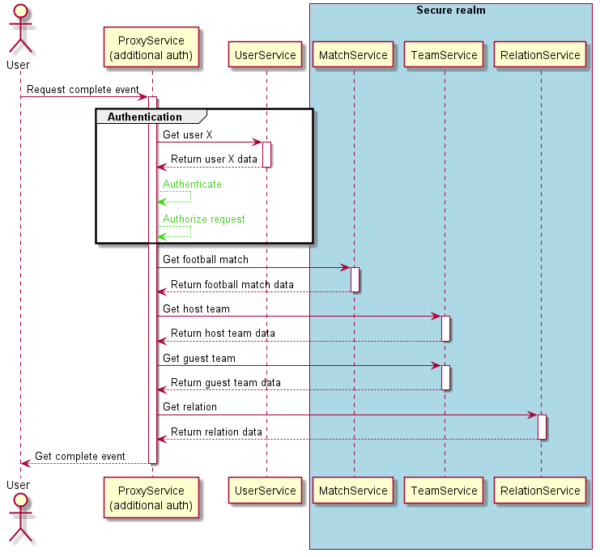
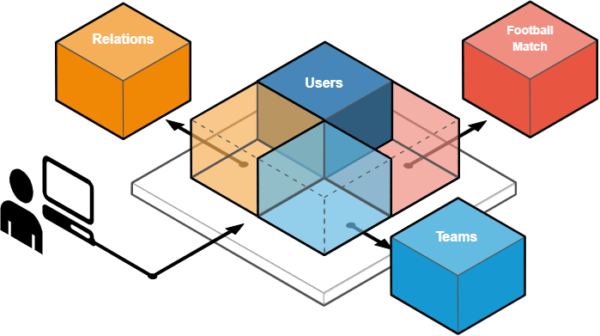
Knowing that we always need to get some user data with each authentication, we can keep the user context as close to the proxy service as possible. The current diagram of our system would look like this:
Service extraction
How does the service extraction look like in the monolithic vs microservices domain?
Consider the microservice definition for a second from the official website, which says that services should be characterized by:
- High testability and ease of maintenance
- Loose connections
- Possibility of independent deployment
- Concentration on business capabilities
- Ownership of one team
You could conclude that the service is a mostly autonomous being. And yes, we can treat it as a separate project with its copy of the framework, settings, and the logic related only to the given context.
That assumption unveils one of the less desirable peculiarities of microservices — duplication.
Get used to the fact that projects in a microservice architecture will often face data duplication as files (framework and vendors) or identifiers in the database. They are necessary for us to deliver all the functionalities.
Let’s use these assumptions in the context of football matches. To transform existing code and business logic into a microservice, we will create a separate project.
The workflow will be repeatable for all contexts:
- Create a new folder for the setup of a framework and necessary packages configurations
Alternatively, copy the current settings and trim them a bit - Only transfer the context-related code to the new project
- Prepare the docker configuration to run services simultaneously
- Test the newly extracted part of the application and apply any final fixes or improvements
Follow this checklist to execute all tasks on it. First, let’s handle the folder structure.
It will be nearly the same as the structure of the current project, except that you will transfer only the elements related to football games.
The catalog with the service will look something close to what’s in this picture.
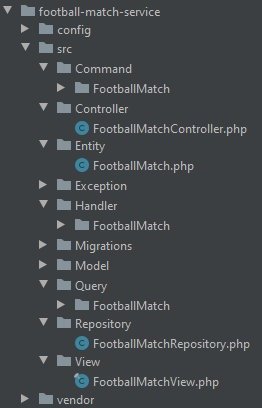
You can see folders related to the Symfony framework, the configuration of the microservice, and namespaces consistent with the division of the CQRS pattern imposed by us earlier.
As the context of football games became a separate project, you need it to run it independently from the rest of the project.
A new definition of a service is required in docker-compose.yml. It will be an entry regarding the folder containing a current service code.
From now on, while entering the command docker-compose up -d in the console, you’ll launch the container for football matches container to run alongside the main project.

💡 Study: Information about docker-compose on the Docker website.
We’ve made quite a few changes to our code, so it’s time to check that everything works.
If you run automatic tests for our service, unfortunately, all the scenarios will turn red.
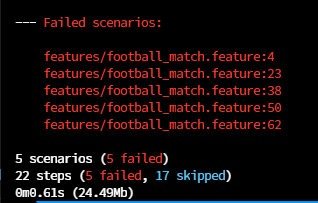
How is that possible if the code was working fine before the extraction?
It turns out that the service has dependencies on system elements with definitions no longer existing in our context.
Those are mainly data models and ORM relationships between entities. Removing the former is not particularly difficult, because identifiers fetch all dependent models.
So, we need to replace the objects with the associated IDs. As an example, we’ll use the entity describing the match. It holds information about points, date, and the two competing teams.
When a person from the administration crew creates a new match, they must enter the names of the host and guest teams from the list.
The application later resolves the dependencies for these objects before writing them into the database. Then, it stores the dependencies in individual columns.
In the current microservice context, we do not have teams, but you can simply provide only identifiers that previously appeared as foreign key identifiers of the corresponding teams.
With these identifiers, you can easily restore the previous structure of the object.
Type 1: M or M: N relationships between classes and foreign keys in the database are more problematic. They introduce strong dependencies between objects that create problems when dividing the system into independent elements.
Foreign keys are often generated automatically without our knowledge when we use tools such as ORM. For example, Doctrine would be one of them.
Many-to-one relationships for teams are defined this way:
Such foreign keys are stored in the database:
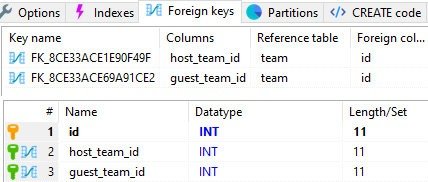
Since we want to remove these keys, we need to alter the database structure.
The app uses a special DROP FOREIGN KEY declaration to delete foreign keys in MySQL We will use it in database migration to ensure that the process is reversible.
💡 Study: MySQL documentation – Foreign Key Constraints
Now, you can remove the many-to-one relationship from the ORM code safely.
Replace the field names with those corresponding to the columns from the database. Remember we established indexes for foreign keys to ensure the optimal performance of queries.
That’s why you should make up for those missing entity declarations.
After removing relationships in the database, we gained the ability to move tables into separate databases.
If there’s ever a need for a change, we can switch the technology or mechanism used to store information.
The time has come for further tests after these alterations.
Fortunately, test scenarios were successful, and no errors were reported.
I want to elaborate on table splitting between different databases.
Consider the consequences of such a move. You will encounter another widespread problem occurring in microservices with transactions.
Getting transactions over several microservices is not an easy thing to achieve when application or system errors break their functionality.
Fortunately, Hector Garcia-Molina and Kenneth Salem documented the first attempt to deal with this problem in 1987 in a document called “Sagas”.
They named two methods for dealing with table splitting:
- The Saga pattern
Defined as a series of consecutive transactions in which each transaction updates data within one service. In case of failure, transactions that compensate changes are performed. - Eventual consistency
It’s a model that does not support the cross-service ACID transaction style (Atomicity, Consistency, Isolation, Durability) in favor of other mechanisms to ensure that data is consistent in the future.
💡 A deeper insight on architectural work
The creation of a proxy microservice
Now that we have separated our microservice and all its logic from the existing code base, it turns out that we cannot use it.
The app must communicate with the newly created microservice somehow to ensure the current functionality of the application.
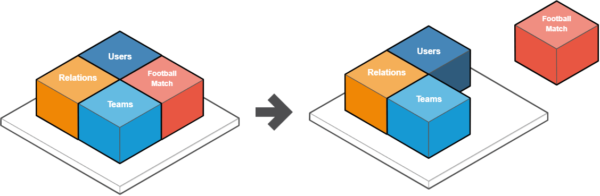
We will create a simple service inside the application to allow transparent control and transmission of data coming from the outside.
The service will be called ServiceEndpointResolver, and its underlying method will be the callService method with parameters such as the HTTP method, microservice address, or data.
Another critical element of the proxy will be the ability to resolve path names to relevant microservices.
To do this, you need to create a simple map describing which endpoint name belongs to which microservice. This way, the EndpointToServiceMap class was formed:
To get the full address of the microservice to which we want to transfer data, prepare another method for the ServiceEndpointResolver class:
You can now combine and use them in the controller method related to football match updates.
Now, we need to handle any errors returned from the service, such as:
- Incorrect data and validation
- Misbehaving service
- Problems with connection
Finally, add a method in the application base controller class to validate the response returned from the microservice.
After all these operations, the application should work again — just like before microservice extraction.
Here’s the new structure diagram:
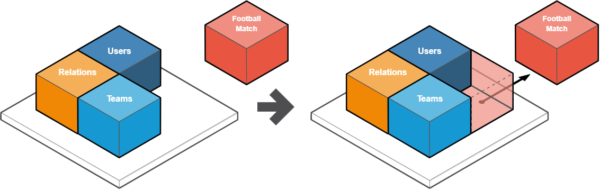
Similarly, let’s proceed with all other microservices from the project.
The only difference in working on them is that you don’t have to isolate the last one, because it won’t have code dependencies from the other microservices.
In the case of this app, leave the logic related to users, authentication, and authorization in place. This way, your proxy microservice will emerge.
Infrastructure and monitoring
The way we run microservices now is rather straightforward. Unfortunately, this solution can’t use all the benefits which microservice architecture gives us.
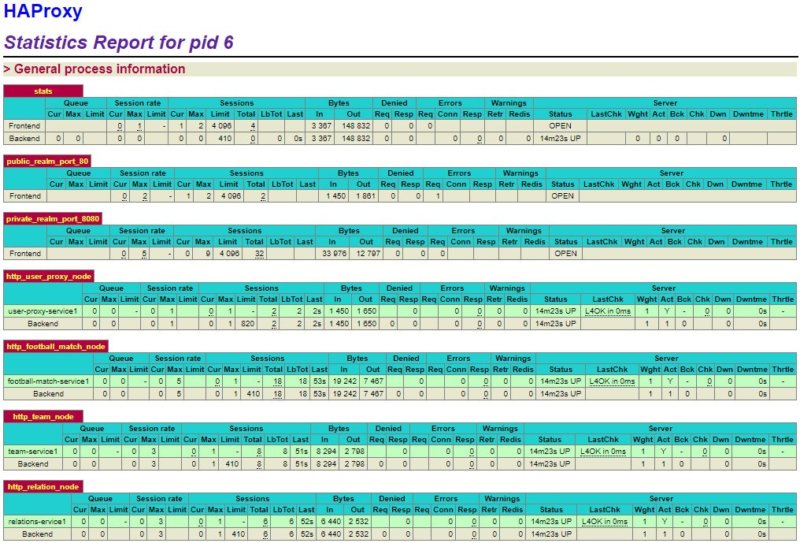
We want to monitor the status of microservices and scale them freely. A load balancer called HAProxy comes to our aid, which will help to provide basic monitoring functionality and support for multiple microservice instances.
💡 Study: Official HAProxy Docker image
As we want to add the HAProxy container to the application, we need to modify the docker-compose.yml file.
Besides, to secure solid communication between containers, we need to set the names of dependent containers. Here’s how:
Bearing in mind that all communication should take place only through our proxy, we are adding an internal network in the Docker called “hidden”.
From now on, the application will receive all traffic through port 80 and redirect to the proxy service.
To ensure convenient addressing, we’ve also added internal microservice domains. All that’s left to do is to create the configuration for the HAProxy.
Divide the file into two sections:
- Frontend
Configures the listening ports and allows you to include control logic for the data that needs forwarding - Backend
Defines the available list of microservers to which traffic is redirected.
From the configuration file, you can easily recognize the connections between Docker container names and the domain names we imposed.
After restarting the application, we should be able to check current services statuses at 127.0.0.1:1936/stats
One of the essential features that microservices have is the ability to scale, allowing the application to optimize resource consumption and improve performance.
In the first part of the article, our fictional customer raised the problem of performance.
The application bends down under heavy traffic during matches of well-known teams. Fortunately, now with the help of the Docker scale and HAProxy commands, we can increase the number of our microservices.
Just remember to load the appropriate configuration file.
💡 Study: Docker – Scale command
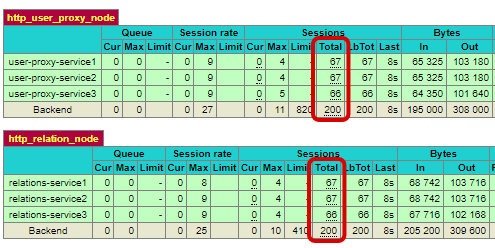
The HAProxy has divided two hundred test queries equally between each microservice after the application was scaled to three server instances.
The proxy’s configuration is so basic that anybody can adapt the load balancer to their own needs at a speed.
Besides, the extensive documentation from an active community will help solve potential errors.
Another thing that we can see on the statistics page is the status of each microservice.
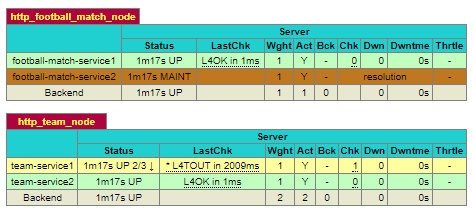
On the statistics page, you’ll see which microservices is unavailable or under heavy load at a glance. There’s also information on how requests are distributed, and how many sessions are currently active.
In the world of microservices, such information is vital to us, as it allows to assess how efficiently various components work inside the application.
Find the updated code for the app in the repository.
Migrating from monolithic to microservices – conclusions
Congrats! You went through all stages of the app’s transformation from a monolithic architecture into a microservices-based architecture. You know how to use the techniques and patterns needed for the migration and what problems you can expect.
We discussed refactoring techniques, DDD, bounded context, and CQRS methodologies.
It is worth noting that the microservices-based architecture can’t fix all problems and even created some new difficulties:
- Greater architectural complexity
As we create new contexts or namespaces, read/write models, and many additional classes - New security threats
More components require more work to keep the entire system secure - Complicated logging and data flow tracking
Information about events is scattered across various elements of the application - More demanding system error handling
We cannot allow a failing service to block the entire system; the entire delivery service gets more complex - Difficulties in the deployment of services
This process must always be coordinated
However, if we plan carefully and stick to good practices, the chances of experiencing problems are minimal. And that is why we see an increasing wave of customers wanting to switch to microservices.
After all, most applications on the Internet were built as a monolith, and ever-changing business requirements force companies to look for new and agile solutions.
I hope that the examples presented in this guide will be helpful for people interested in the migration process for their new architecture.
Are you interested in migrating from monolithic to microservices?
The Software House has completed a lot of such projects, helping various clients get the most value out of it, avoiding common pitfalls altogether. Let’s talk about your migration project!

